Ich sage voraus, dass die Formel für die nächsten 10,000 Startups darin besteht, dass man etwas nimmt und KI hinzufügt. Wir werden das millionenfach wiederholen, und es wird wirklich riesig.
Ein paar Jahre zurück, hier sind wir.
Sie können sehen, wie jede Branche bisher von KI berührt wurde.
Und der interessante Teil? Wir stehen noch am Anfang dieses Prozesses, in dem die nächste Multi-Billionen-Dollar-Industrie entsteht.
Der Wendepunkt für mich war beruflich 2019 mit GPT-2, seit ich eine Explosion von Cloud-basierten Unternehmen (IaaS, PaaS und SaaS) gesehen habe, die verschiedene Arten von KI-basierten Diensten anbieten.
Aus dem Geschäft Analyse Bei der Generierung von Inhalten, der Optimierung und vielen anderen Diensten scheint die KI Hand in Hand mit einer Cloud-basierten Infrastruktur zu gehen.
Kurz gesagt, KI-Modelle, die eine enorme Rechenleistung erfordern, haben eine ganze Industrie von IaaS, PaaS und SaaS weiter angespornt.
Aber es steckt noch viel mehr dahinter.
KI hat ein ganz neues Entwickler-Ökosystem angespornt, das sowohl aus Open-Source- als auch proprietären Tools besteht, die größtenteils kostenlos sind und von IaaS-Spielern genutzt werden, um ihre Cloud-basierten Dienste attraktiver zu machen.
Wir werden sehen, wie das Ganze funktioniert.
Aber wenn wir den KI-Geschäftsmodellen eine Struktur geben würden, wie würde das funktionieren?
Lassen Sie mich zunächst einige Dinge klarstellen.
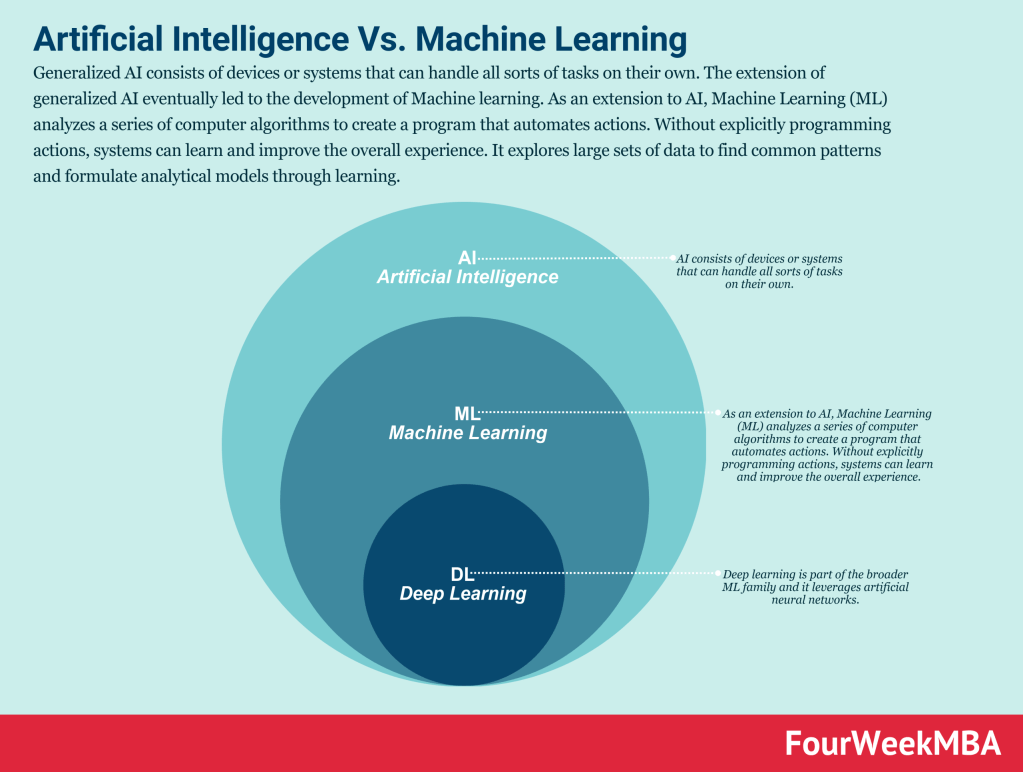
Deep Learning ist eine Teilmenge des maschinellen Lernens, das eine Teilmenge der KI ist.
Kurz gesagt, wenn Sie jemanden über KI sprechen hören, ist das so allgemein, dass es eigentlich gar nichts bedeutet.
Für ein größeres Publikum hilft das Erklären von Dingen in Bezug auf KI jedoch mehr Menschen zu verstehen, worüber wir sprechen.
Tatsächlich geht es bei KI, wenn Sie möchten, einfach darum, alles intelligenter zu machen.
Maschinelles Lernen zielt stattdessen darauf ab, Modelle/Algorithmen zu erstellen, die lernen und sich im Laufe der Zeit verbessern können.
Und Deep Learning ist eine weitere Untergruppe des maschinellen Lernens, das darauf abzielt, das menschliche Lernen nachzuahmen (wie wir sehen werden, ist die Art und Weise, wie die Maschine zu Ergebnissen kommt, natürlich völlig anders als die des Menschen).
Diese Deep-Learning-Modelle haben sich bei der erfolgreichen Durchführung sehr komplexer Aufgaben als ziemlich unglaublich erwiesen. Besonders in zwei Bereichen: Verarbeitung natürlicher Sprache und Computer Seh-.
Transformer-basierte Architektur, es dreht sich alles um Aufmerksamkeit
Der eigentliche Wendepunkt für die KI-Branche kam 2017. Seit den frühen 2000er Jahren erlebte die KI-Welt dank Deep Learning eine Renaissance.
Tatsächlich wurde der Begriff Deep Learning Anfang der 2000er Jahre immer mehr mit tiefen neuronalen Netzen in Verbindung gebracht.
Einer der Durchbrüche kam, als sein Team zeigte, dass es möglich ist, eine einzelne Schicht von Neuronen mit einem Autoencoder zu trainieren.
Das alte Paradigma
Wie Geoffrey Hinton in seinem TED im Jahr 2018 den Unterschied zwischen dem alten und dem neuen Paradigma erklärte:
Wenn Sie möchten, dass ein Computer etwas tut, besteht die alte Methode darin, ein Programm zu schreiben. Das heißt, Sie finden selbst heraus, wie Sie es tun, und es steckt in den Details, Sie sagen dem Computer genau, was er tun soll, und die Computer mögen Sie, aber schneller.
Kurz gesagt, in diesem alten Paradigma ist es der Mensch, der das Problem herausfindet und ein Softwareprogramm schreibt, das dem Computer genau sagt, wie er dieses Problem ausführen soll.
Da der Computer jedoch extrem schnell ist, wird er ihn sehr gut ausführen.
Dieses alte Paradigma sagt Ihnen jedoch auch, dass die Maschine keine Flexibilität hat. Es kann nur die eng begrenzte Aufgabe erfüllen, die ihm übertragen wurde.
Und damit die Maschine die Aufgabe effektiver ausführen konnte, war eine kontinuierliche Verbesserung durch den Menschen erforderlich, der die Software aktualisieren und Codezeilen hinzufügen musste, um die Maschine für die Aufgabe effizienter zu machen.
Das neue Paradigma
Im neuen Paradigma, wie Geoffrey Hinton erklärt:
Der neue Weg ist, dass Sie dem Computer sagen, er soll so tun, als wäre er in Ihrem Netzwerk mit einem Lernalgorithmus, der programmiert, aber danach, wenn Sie ein bestimmtes Problem lösen wollen, zeigen Sie einfach Beispiele.
Das ist die Essenz von Deep Learning.
Ein Beispiel, erklärt Geoffrey Hinton, ist das Erkennen eines Bildes durch die Maschine:
Angenommen, Sie möchten das Problem lösen, dass ich Ihnen alle Pixel im Bild gebe. Das sind drei Zahlen pro Pixel für die Farbe, sagen wir, eine Million davon, und Sie müssen diese drei Millionen Zahlen in eine Reihe von Wörtern umwandeln. Das sagt, was in dem Bild ist, das ein kniffliges Programm zu schreiben ist. Die Leute haben es 50 Jahre lang versucht und sind nicht einmal in die Nähe gekommen, aber jetzt kann ein neuronales Netz es einfach.
Warum ist das so wichtig?
Nun, weil es keine Rolle mehr spielt, ob der Mensch in der Lage ist, ein Programm zu schreiben, um das Bild zu erkennen.
Weil die Maschine, die ein neuronales Netz nutzt, das Problem lösen kann.
Wie kommt es, dass sie dieses Problem 50 Jahre lang nicht lösen konnten und es dann doch taten?
Die radikale Änderung bestand in der Verwendung künstlicher Neuronen, die in der Lage waren, die empfangenen Eingaben einzuwägen und als Ausgabe eine nichtlineare Funktion zu erzeugen (die lineare Eingaben in nichtlineare Ausgaben übersetzen konnte), was sich als ziemlich effektiv herausstellte komplexere Aufgaben.
Ein Schlüsselelement dieser tiefen Netzwerke ist eine bestimmte nichtlineare Funktion, die als Aktivierungsfunktion bezeichnet wird.
Heutzutage sind maschinelle Lernmodelle wie GPT-3 von OpenAI, BERT von Google und Gato von DeepMind allesamt tiefe neuronale Netze.
Diese verwenden eine partikuläre Architektur, die als transformatorbasiert bezeichnet wird.
In einem Papier aus dem Jahr 2017 mit dem Titel „Aufmerksamkeit ist alles was Sie brauchen“ (Das liegt daran, dass ein Mechanismus namens „Aufmerksamkeitsmechanismus“ der Trigger von Neuronen innerhalb des neuronalen Netzwerks ist, das in das Ganze übergeht Modell).
Sie präsentierten diese neue, unglaubliche Architektur für ein tiefes Lernen Modell, genannt Transformer-based, die die gesamte KI-Industrie erschlossen hat, insbesondere im Bereich der Verarbeitung natürlicher Sprache, Computer Seh-, Selbstfahren und einige andere Bereiche.
Wie wir sehen werden, hat diese Architektur so leistungsstarke Modelle für maschinelles Lernen hervorgebracht, dass einige so weit gegangen sind, sich eine sogenannte AGI (künstliche allgemeine Intelligenz) vorzustellen.
Oder die Fähigkeit von Maschinen, viele Aufgaben flexibel zu lernen und dabei möglicherweise Empfindungsvermögen zu entwickeln. Wie wir sehen werden, ist dies noch lange nicht der Fall. Zum einen wollen wir hier verstehen, welche Auswirkungen diese maschinellen Lernmodelle auf die Geschäftswelt haben.
Wir werden uns das Potenzial ansehen und Geschäftsmodelle die sich dank dieser maschinellen Lernmodelle entwickeln können? Wir werden uns sowohl das Ökosystem des Entwicklers als auch das ihn umgebende Geschäftsökosystem ansehen.
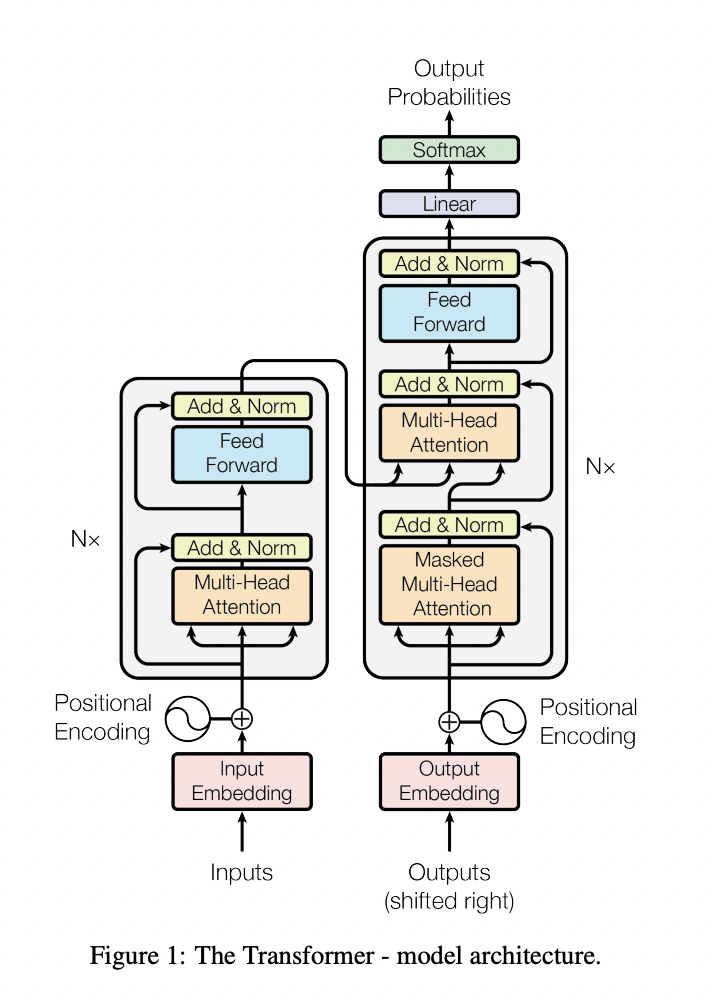
Werfen wir einen kurzen Blick auf die Architektur dieser tiefen neuronalen Netze, um zu verstehen, wie sie auf einer grundlegenden Ebene funktionieren:
Quelle: Aufmerksamkeit ist alles, was Sie brauchen, 2017
Seitdem sind Transformers die Grundlage aller bahnbrechenden Modelle wie Google BERT und OpenAI GPT3.
Ein Transformator Modell ist ein neuronales Netzwerk, das den Kontext und damit die Bedeutung lernt, indem es Beziehungen in sequentiellen Daten wie den Wörtern in diesem Satz verfolgt.
Wie NVIDIA erklärt, sind daher Anwendungen, die sequenziellen Text, Bild- oder Videodaten verwenden, ein Kandidat für Transformer-Modelle.
In einer KrepppapierIm Jahr 2021 hoben Forscher aus Stanford hervor, wie transformatorbasierte Modelle zu grundlegenden Modellen geworden sind.
Quelle: Zu Chancen und Risiken von Stiftungsmodellen
Wie im selben Artikel erklärt:
Die Geschichte der KI war eine Geschichte des zunehmenden Auftauchens und der Homogenisierung. Mit der Einführung des maschinellen Lernens ergibt sich (automatisch abgeleitet) aus Beispielen, wie eine Aufgabe ausgeführt wird; Mit Deep Learning entstehen die High-Level-Features, die für die Vorhersage verwendet werden; und mit Basismodellen entstehen sogar erweiterte Funktionalitäten wie z. B. kontextbezogenes Lernen. Gleichzeitig homogenisiert maschinelles Lernen Lernalgorithmen (z. B. logistische Regression), Deep Learning homogenisiert Modell Architekturen (z. B. Convolutional Neural Networks) und Basismodelle homogenisieren die Modell selbst (z. B. GPT-3).
Der Aufstieg grundlegender Modelle
Die zentrale Idee der grundlegenden Modelle und der transformatorbasierten Architektur entstand aus der Idee, „Wissen“ (oder die Fähigkeit, eine Aufgabe zu lösen) von einer Domäne in eine andere zu übertragen.
Wie im selben Artikel erklärt:
Die Idee des Transferlernens besteht darin, das „Wissen“ aus einer Aufgabe (z. B. Objekterkennung in Bildern) auf eine andere Aufgabe (z. B. Aktivitätserkennung in Videos) anzuwenden.
Kurz gesagt:
Innerhalb von Deep Learning ist Vortraining der vorherrschende Ansatz zum Transferlernen: a Modell wird auf eine Ersatzaufgabe (oft nur als Mittel zum Zweck) trainiert und dann durch Feintuning an die interessierende nachgelagerte Aufgabe angepasst
Daher haben wir drei Kernmomente für das maschinelle Lernen Modell:
Vortraining: anpassen Modell von einer Aufgabe zur nächsten (stellen Sie sich zum Beispiel vor, Sie haben eine Modell die Produktbeschreibungen generiert, die für einen sinnvoll sind Marke. Jetzt möchten Sie, dass es Produktbeschreibungen generiert, die für andere sinnvoll sind Marke. Dinge wie Tonfall und Zielgruppe ändern sich. Dies bedeutet, dass in Ordnung für die Modell an einem anderen zu arbeiten Marke, es muss vortrainiert werden).
Testen: um die zu validieren Modell, und verstehen Sie, wie es sich auf breiterer Ebene „verhält“ (z. B. ist es eine Sache, eine Modell das Produkte generiert
Und Feintuning: oder machen die Modell besser und besser für die anstehende Aufgabe, indem Sie sowohl an Eingaben arbeiten (Daten, die in die Modell) und Ausgabe (Analyse der Ergebnisse der Modell).
Was diesmal anders ist, ist die schiere Größe dieser Modelle.
Und eine Skalierung ist möglich (wie in der grundlegenden Modell's paper) durch drei Hauptzutaten:
Hardware (Übergang von CPU zu GPU, wobei Unternehmen wie NVIDIA auf die Farm-on-Chips-Architektur für KI setzen).
Weiterentwicklung des Transformators Modell die Architektur.
Und die Verfügbarkeit von viel mehr Trainingsdaten.
Anders als früher, als die Daten gekennzeichnet werden mussten, um verwendet zu werden. Moderne Modelle für maschinelles Lernen (wie Googles BERT) sind in der Lage, Aufgaben selbstüberwacht und mit unbeschrifteten Daten auszuführen.
Die bahnbrechenden Deep-Learning-Modelle (BERT, GPT-3, RoBERTa, BART, T5) basieren auf selbstüberwachtem Lernen in Verbindung mit der Transformer-Architektur.
Die Grundidee ist, dass eine einzige Modell könnte für ein so breites Spektrum von Aufgaben nützlich sein.
Die Transformatorenindustrie ist explodiert, und immer mehr kommen auf den Markt.
Aus der Homogenisierung und Skalierung dieser Modelle ergab sich ein interessantes Merkmal.
Durch Skalierung der verfügbaren Parameter auf a Modell (GPT-3 verwendete 175 Milliarden Parameter im Vergleich zu 2 Milliarden GPT-1.5) es ermöglichte kontextbezogenes Lernen.
Während es gleichzeitig unerwartet auftauchte prompt, oder eine Beschreibung der Aufgabe in natürlicher Sprache), die verwendet werden kann, um die zu verfeinern Modell und es für andere nachgelagerte Aufgaben (eine bestimmte Aufgabe, die Sie lösen möchten) zum Laufen bringen.
Quelle: Zu Chancen und Risiken von Stiftungsmodellen
Grundlegende Modelle sind extrem leistungsfähig, weil sie bisher vielseitig sind. Aus Daten, seien sie beschriftet und strukturiert oder unbeschriftet und unstrukturiert, die Grundlage Modell kann sich anpassen, um verschiedene Aufgaben zu generieren.
Das Gleiche Modell kann die Beantwortung von Fragen, Stimmung durchführen Analyse, Bildbeschriftung, Objekterkennung und Befolgen von Anweisungen.
Um auf die Idee zu kommen, hat OpenAI eine Spielplatz für GPT-3. Ein einzelnes Modell kann für eine Vielzahl von Aufgaben verwendet werden. Von Fragen und Antworten über Grammatikkorrekturen, Übersetzungen, Klassifizierungen, Stimmungsanalysen und vieles mehr.
In dieser Hinsicht, Aufforderung (oder die Fähigkeit, die Maschine dazu zu bringen, eine ganz bestimmte Aufgabe auszuführen) wird in Zukunft eine entscheidende Fähigkeit sein.
In der Tat wird die Eingabeaufforderung entscheidend sein, um Kunst, Spiele, Code und vieles mehr zu generieren.
Es ist die Eingabeaufforderung, die Sie von der Eingabe zur Ausgabe bringt.
Und die Qualität der Eingabeaufforderung (die Fähigkeit, die Aufgabe zu beschreiben, das maschinelle Lernen Modell ausführen muss) bestimmt die Qualität der Ausgabe.
Ein weiteres Beispiel dafür, wie KI verwendet wird, um jedem das Programmieren zu ermöglichen, ist der KI-Copilot von GitHub:
Der GitHub-KI-Copilot schlägt Code und ganze Funktionen in Echtzeit vor.
Wir müssen von den Grundschichten ausgehen.
Beginnen wir damit, das Ganze zunächst aus der Sicht der Entwickler zu analysieren, die Modelle zu bauen und sie der Öffentlichkeit bereitzustellen.
Und dann bewegen wir uns auf die andere Seite des Spektrums und betrachten das geschäftliche Ökosystem drumherum.
Der Workflow des Machine Learning-Modells
Quelle: Zu Chancen und Risiken von Stiftungsmodellen
Die erste Frage, die sich stellen sollte, ist, wenn ein Entwickler Modelle für maschinelles Lernen von Grund auf neu erstellen möchte, wo ist der richtige Ort, um basierend auf dem Workflow zum Erstellen eines Modells zu beginnen Modell von Grund auf neu?
In diesem Fall gibt es verschiedene Software für maschinelles Lernen, die KI-Entwickler nutzen können.
In diesem Sinne ist es wichtig zu verstehen, was ein Workflow zum Erstellen eines maschinellen Lernens ist Modell, und die verschiedenen Komponenten, die der Entwickler benötigt.
Im Allgemeinen erstellen Entwickler Modelle für maschinelles Lernen, um bestimmte Aufgaben zu lösen.
Nehmen wir den Fall eines Entwicklers, der einen bauen möchte Modell die Produktseitenbeschreibungen für eine große E-Commerce-Website generieren können.
Der Arbeitsablauf sieht wie folgt aus:
Datenerstellung. In dieser Phase sammelt der Mensch die Daten, die für die benötigt werden Modell um bestimmte Aufgaben auszuführen (wenn Sie beispielsweise Produktbeschreibungen generieren möchten, möchten Sie möglichst viel Text und Daten zu vorhandenen Produkten).
Datenpflege. Dies ist entscheidend, um die Qualität der Daten zu gewährleisten, die in das eingehen Modell. Und auch dies ist normalerweise meist menschlich zentriert.
Ausbildung. Dies ist der Teil des Brauchs Modell Erstellung basierend auf den gesammelten und kuratierten Daten.
Anpassung. In dieser Phase ausgehend vom Bestehenden Modell, wir trainieren es vorab, um neue Aufgaben auszuführen (denken Sie an den Fall der Verwendung von GPT-3, um Produktseiteninhalte auf einer bestimmten Website zu erstellen. Dazu muss das Modell für den Kontext dieser Website vorab trainiert werden, um generieren zu können relevanten Inhalt).
Einsatz. Die Phase, in der das Modell der Welt zugänglich gemacht wird.
Ich möchte hinzufügen, dass Sie in den meisten kommerziellen Anwendungsfällen vor der Bereitstellung normalerweise mit einem Pilotprojekt beginnen, das den Zweck hat, eine sehr einfache Frage zu beantworten.
Kann das Modell beispielsweise Produktseiten erstellen, die für den Menschen sinnvoll sind?
In diesem Zusammenhang ist der Umfang begrenzt (Sie beginnen beispielsweise mit der Generierung von maximal 100-500 Produktseiten).
Und wenn es funktioniert, beginnen Sie mit der Bereitstellung.
Danach, basierend auf dem, was ich gesehen habe, sind die nächsten Phasen:
Iteration: oder sicherstellen, dass das Modell verbessert werden kann, indem ihm mehr Daten zur Verfügung gestellt werden.
Feintuning: oder sicherstellen, dass das Modell durch Datenpflege erheblich verbessert werden kann.
Skalieren: Aktivierung des Modells auf immer größeren Volumes für diese spezielle Aufgabe.
Lassen Sie uns auf der Grundlage des oben Gesagten das Entwickler-Ökosystem für KI rekonstruieren.
MLOps: Ökosystem des Entwicklers
Machine Learning Ops (MLOps) beschreibt eine Reihe von Best Practices, die einem Unternehmen dabei helfen, künstliche Intelligenz erfolgreich zu betreiben. Es besteht aus den Fähigkeiten, Arbeitsabläufen und Prozessen zum Erstellen, Ausführen und Warten von Modellen für maschinelles Lernen, um verschiedene betriebliche Prozesse in Organisationen zu unterstützen.
Bevor wir zu den Besonderheiten des Entwickler-Workflows kommen, beginnen wir mit einer ganz einfachen Frage.
Wie programmiert man ein maschinelles Lernmodell? Welche Sprache benutzt du?
Nachfolgend sind die beliebtesten Programmiersprachen im Jahr 2022 laut GitHub-Statistiken aufgeführt:
madnight.github.io/githut/#/pull_requests/2022/1
Sagt es dir etwas? Python, die beliebteste Programmiersprache, ist auch die beliebteste KI-Programmiersprache.
In der Liste der Top-Programmiersprachen sind natürlich einige nicht für KI. Aber die Top XNUMX, Python, JavaScript und Java, sind die beliebtesten für die KI-Programmierung.
Python ist bei weitem das beliebteste.
Aufgrund seiner Einfachheit, aber auch dank der Tatsache, dass es Programmierern eine Reihe von Bibliotheken zur Verfügung stellt, aus denen sie schöpfen können, und dass es interoperabel ist.
Datenerstellung
Der Teil der Datenerstellung ist eine auf den Menschen ausgerichtete intensive Aufgabe, die äußerst wichtig ist, da die Qualität der zugrunde liegenden Daten die Qualität der Ausgabe des Modells bestimmt.
Wenn man bedenkt, dass die Daten auch das Modell trainieren, so ist eine etwaige Verzerrung durch dieses Modell auf die Art und Weise zurückzuführen, wie die Daten ausgewählt wurden.
In der Regel kann ein Modell entweder mit realen Daten oder mit synthetischen Daten trainiert werden.
Denken Sie bei realen Daten an den Fall, wie Tesla die Milliarden von Kilometern nutzt, die von Tesla-Besitzern auf der ganzen Welt gefahren wurden, um seine selbstfahrenden Algorithmen durch seine Deep-Learning-Netzwerke zu verbessern.
Die selbstfahrenden neuronalen Netze von Tesla nutzen die Milliarden von Kilometern, die von Tesla-Besitzern gefahren werden, um die selbstfahrenden Algorithmen mit jeder neuen Softwareversion zu verbessern!
Synthetische Daten hingegen werden über Computersimulationen oder Algorithmen in der digitalen Welt erzeugt.
Mit Python in NVIDIA Omniverse können KI-Programmierer Daten direkt aus einer virtuellen Umgebung generieren. Da es sich um Daten handelt, die in der realen Welt nicht existieren, aber synthetisch generiert werden, können sie zum Vortrainieren von KI-Modellen verwendet werden und werden tatsächlich als synthetische Daten bezeichnet.
Im Allgemeinen ist es eine Frage der Wahl zwischen realen Daten und synthetischen Daten. Nicht alle Unternehmen haben die Möglichkeit, auf eine breite Palette von Daten aus der realen Welt zuzugreifen.
Beispielsweise haben Unternehmen wie Tesla, Apple oder Google mit erfolgreichen Hardwaregeräten auf dem Markt (Tesla-Autos, iPhone, Android-Smartphones) die Möglichkeit, eine riesige Menge an Daten zu sammeln und diese zu verwenden, um ihre Modelle vorzutrainieren und zu verbessern KI-basierte Produkte schnell.
Andere Unternehmen haben diese Änderung möglicherweise nicht, sodass die Nutzung synthetischer Daten schneller, billiger und in einigen Fällen datenschutzorientierter sein kann.
Tatsächlich hat der Aufstieg der KI-Industrie bereits andere angrenzende Branchen angespornt, wie die Branche der Anbieter synthetischer Daten.
ZumoLabs, das Synthetic Data Ecosystem, aktualisiert im Oktober 2021
Datenkuration
Sobald Sie die Daten erhalten haben, dreht sich alles um die Kuration. Die Datenkuratierung ist ebenfalls zeitaufwändig und dennoch kritisch, da sie die Qualität des von Ihnen erstellten benutzerdefinierten Modells bestimmt.
Auch wenn es um Datenpflege geht, gibt es eine ganze Branche dafür.
Ausbildung
Für den Trainingsteil gibt es dafür verschiedene Software. Das Training von Modellen für maschinelles Lernen ist das Herzstück des gesamten Workflows. Tatsächlich ermöglicht das Training die Anpassung der Modelle.
In diesem Zusammenhang haben Cloud-Infrastrukturen erheblich investiert, um Tools zu erstellen, die KI-Programmierern und -Entwicklern helfen. Einige dieser Tools sind Open Source, andere sind proprietär.
Im Allgemeinen sind KI-Tools eine kritische Komponente für beide Cloud-Infrastrukturen, die Entwicklergemeinschaften rund um diese Tools unterstützen und somit ihre Cloud-Angebote verbessern können.
Kurz gesagt, das KI-Tool ist das „Freemium“, das dazu dient, die Marke des Cloud-Anbieters und fordert Entwickler auf, ihre Modelle auf ihren Cloud-Infrastrukturen zu hosten.
Nicht zufällig stammen die am häufigsten verwendeten KI-Tools von Unternehmen wie Amazon AWS, Google Cloud, IBM und Microsofts Azure.
Die Veröffentlichung eines KI-Tools, entweder als Open Source oder als proprietäres, ist nicht nur eine philosophische Entscheidung, sondern auch eine Geschäftsmodell Wahl.
Bei einem Open-Source-Ansatz wird das KI-Tool tatsächlich nur dann monetarisiert, wenn das Modell auf derselben Cloud-Infrastruktur gehostet wird, kurz gesagt, es funktioniert als Premium.
So sieht das Ökosystem der Tools aus, wenn Sie versuchen, KI-Tools zu entwickeln. All-in-One-Lösungen werden entwickelt, um die Fragmentierung der Werkzeuge im KI-Ökosystem auszugleichen.
Analysieren wir nun das gesamte Geschäftsökosystem und wie es um diese Modelle des maschinellen Lernens herum organisiert wurde.
Das KI-Business-Ökosystem
Cloud Geschäftsmodelle basieren alle auf Cloud Computing, einem Konzept, das um 2006 aufkam, als der ehemalige CEO von Google, Eric Schmit, es erwähnte. Die meisten Cloud-basiert Geschäftsmodelle kann als IaaS (Infrastructure as a Service), PaaS (Platform as a Service) oder SaaS (Software as a Service) klassifiziert werden. Während diese Modelle hauptsächlich über Abonnements monetarisiert werden, werden sie über nutzungsbasierte Umsatzmodelle und Hybridmodelle (Abonnements + nutzungsbasierte Bezahlung) monetarisiert.
Chip-Architektur
Mit dem Aufstieg der KI haben einige Tech-Player alles in die Herstellung von Chips für die KI investiert. Ein Beispiel ist NVIDIA, die eine ganz neue Kategorie der Chiparchitektur geschaffen hat, basierend auf GPU, deren Architektur gut für KI geeignet ist, schweres Heben.
NVIDIA ist eine GPU Design Unternehmen, das Unternehmenschips für Branchen entwickelt und vertreibt, die von Gaming, Rechenzentren, professionellen Visualisierungen und autonomem Fahren abhängen. NVIDIA bedient große Konzerne als Unternehmenskunden und nutzt eine Plattform Strategie wo es seine Hardware mit Softwaretools kombiniert, um die Fähigkeiten seiner GPUs zu verbessern.
Andere Unternehmen wie Intel und Qualcomm konzentrieren sich ebenfalls auf KI-Chips.
Jedes dieser Unternehmen mit einem besonderen Schwerpunkt.
Beispielsweise erweisen sich die KI-Chips von NVIDIA als äußerst leistungsfähig für Spiele, Rechenzentren und professionelle Visualisierungen.
Selbstfahrende und intelligente Maschinen sind jedoch auch kritische Bereiche, auf die NVIDIA setzt.
Auch Intel interessiert sich massiv für KI-Chips, was zu seinen Prioritäten gehört.
Und unten sehen Sie, wie jedes seiner Chipprodukte in verschiedenen KI-betriebenen Branchen eingesetzt wird.
Qualcomm bietet auch einen Stapel Chips für verschiedene Anwendungsfälle.
Im Allgemeinen haben Technologiegiganten die Herstellung von Chips jetzt ins eigene Haus gebracht.
Ein Beispiel ist Apple, das endlich damit begann, eigene Chips sowohl für seine Telefone als auch für Computer zu produzieren.
Google ist diesem Beispiel gefolgt, indem es seine eigenen Chips für die neuen Generationen von Pixel-Telefonen entwickelt hat.
Ein neuer Chip, der zum ersten Mal im eigenen Haus entwickelt wurde, wurde als Premium-System auf einem Chip (SoC) gebaut.
Quelle: Google
Diese Chiparchitektur, so behauptet Google, ermöglicht es dem Unternehmen, seine Geräte durch maschinelles Lernen weiter zu verbessern. Zum Beispiel mit Live-Übersetzungen von einer Sprache in die andere.
Warum investieren Unternehmen wieder in Chips?
Mit dem Aufstieg der KI und der Herstellung von allem, was intelligent ist, leben wir an der Schnittstelle verschiedener neuer Branchen, die die KI-Revolution vorantreiben (5G, IoT, Modelle für maschinelles Lernen, Bibliotheken und Chiparchitektur).
Daher ist die Chipherstellung wieder zu einem zentralen strategischen Vermögenswert für Unternehmen geworden, die Hardware für Verbraucher herstellen.
Die drei Ebenen der KI
Was macht ein KI-Geschäftsmodell aus?
Kurz gesagt, wir können die Struktur einer KI analysieren Geschäftsmodell durch Betrachtung von vier Hauptebenen:
OpenAI hat die grundlegende Ebene der KI-Industrie aufgebaut. Mit großen generativen Modellen wie GPT-3 und DALL-E bietet OpenAI API-Zugriff für Unternehmen, die Anwendungen auf der Grundlage ihrer grundlegenden Modelle entwickeln möchten, während sie diese Modelle in ihre Produkte integrieren und diese Modelle mit proprietären Daten und zusätzlicher KI anpassen können Merkmale. Andererseits veröffentlichte OpenAI auch ChatGPT, das sich um ein Freemium-Modell herum entwickelte. Microsoft vermarktet Opener-Produkte auch durch seine Handelspartnerschaft.
Stability AI ist die Entität hinter Stable Diffusion. Stability verdient Geld mit unseren KI-Produkten und mit der Bereitstellung von KI-Beratungsdiensten für Unternehmen. Stability AI monetarisiert Stable Diffusion über die APIs von DreamStudio. Während es es auch als Open Source für jedermann zum Herunterladen und Verwenden freigibt. Stability AI verdient auch Geld über Unternehmensdienste, bei denen das Kernentwicklungsteam Unternehmenskunden die Möglichkeit bietet, Stable Diffusion oder andere große generative Modelle zu warten, zu skalieren und an ihre Bedürfnisse anzupassen.
Gennaro ist der Schöpfer von FourWeekMBA, das allein im Jahr 2022 rund vier Millionen Geschäftsleute erreichte, darunter C-Level-Führungskräfte, Investoren, Analysten, Produktmanager und aufstrebende digitale Unternehmer | Er ist auch Director of Sales für ein Hightech-Scaleup in der KI-Industrie | Im Jahr 2012 erwarb Gennaro einen internationalen MBA mit Schwerpunkt auf Unternehmensfinanzierung und Geschäftsstrategie.