Last Updated: April 2026 — Enhanced with AI business impact analysis
Last Updated: April 2026 — Enhanced with AI business impact analysis
BUSINESS MODEL
AI Business Models
I predict that the formula for the next 10,000 startups is that you take something and you add AI to it. We’re going to repeat that by a million times, and it’s going to be really huge.
Key Components
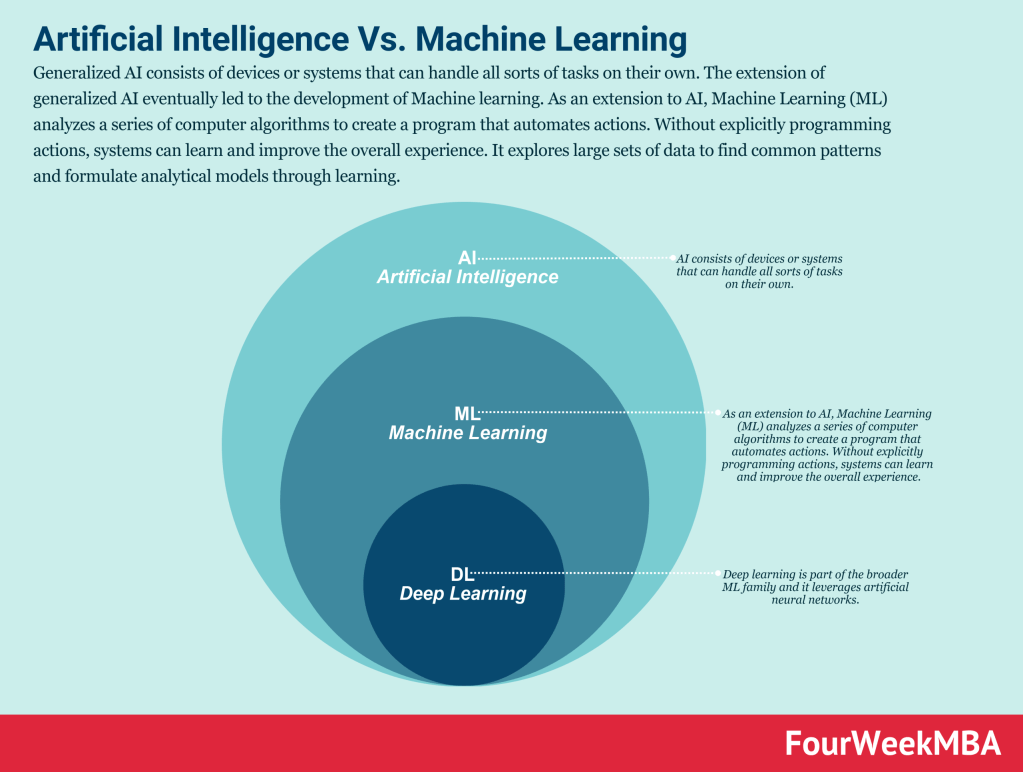
AI today is mostly deep learning
Deep learning is a subset of machine learning, which is a subset of AI.
Transformer-based architecture, it’s all about attention
The real turning point, for the AI industry, came in 2017. Since the early 2000s, the AI world was living a renaissance, thanks to deep learning.
The first question to ask, is if a developer wants to build machine learning models from scratch, where’s the right place to start based on the workflow to build a model from…
MLOps: Developer’s Ecosystem
Before we get to the specifics of the developers’ workflow, let’s start with a very simple question.
What makes up an AI Business Model?
In short, we can analyze the structure of an AI business model by looking at four main layers:
Real-World Examples
AmazonAppleMetaGoogleIbmIntel
Key Insight
The story of AI has been one of increasing emergence and homogenization. With the introduction of machine learning, how a task is performed emerges (is inferred automatically) from examples; with deep learning, the high-level features used for prediction emerge; and with foundation models, even advanced functionalities such as in-context learning…
I predict that the formula for the next 10,000 startups is that you take something and you add AI to it. We’re going to repeat that by a million times, and it’s going to be really huge.
A few years back, here we are.
You can see, how, every industry, so far, has been touched by AI.
And the interesting part? We’re still at the beginning of this process, which is where the next multi-trillion dollar industry is getting created.
The turning point for me, professionally, has been 2019, with GPT-2, ever since I’ve seen an explosion of cloud-based companies (IaaS, PaaS, and SaaS) providing various types of AI-based services.
From business analysis to content generation, optimization, and many other services, the AI seems to be walking hand in hand with cloud-based infrastructure — as explored in the economics of AI compute infrastructure — .
In short, AI models, requiring massive computational power, further spurred a whole industry, of IaaS, PaaS, and SaaS.
But there is way more to it.
AI has spurred a whole new developers’ ecosystem, comprised of both open source and proprietary tools, which are mostly free, that are getting used by IaaS players to make their cloud-based services more appealing.
We’ll see how this whole thing works.
But if we were to give a structure to the AI business models, how would this work?
Deep learning is a subset of machine learning, which is a subset of AI.
In short, if you hear someone talking about AI, that is so generic that it doesn’t really mean anything at all.
However, for the larger audience, explaining things, in terms of AI, helps more people to understand what we talk about.
In fact, if you wish, AI is simply about making anything smarter.
Machine learning, instead, aims at creating models/algorithms that can learn and improve over time.
And deep learning is a further sub-set of machine learning, which aims at mimicking how humans learn (of course, as we’ll see the way the machine gets to outcomes is completely different from how the human does).
These deep learning models have turned pretty incredible in successfully performing very complex tasks. Especially in two domains: natural language processing and computer vision.
Transformer-based architecture, it’s all about attention
The real turning point, for the AI industry, came in 2017. Since the early 2000s, the AI world was living a renaissance, thanks to deep learning.
In fact, by the early 2000s, the term deep learning started to be more and more associated with deep neural networks.
One of the breakthroughs, came when, and his team, showed it was possible to train a single layer of neurons by using an autoencoder.
The old paradigm
As Geoffrey Hinton explained in his TED, back in 2018, the difference between the old and new paradigms:
If you want a computer to do something the old way to do it is to write a program. That is you figure out how you do it yourself, and its squeeze in the details, you tell the computer exactly what to do and the computers like you, but faster.
In short, in this old paradigm, is the human who figures out the problem, and writes a software program, which tells the computer exactly how to execute that problem.
Since though, the computer is extremely fast, it will perform it extremely well.
Yet, this old paradigm, also tells you that the machine has no flexibility. It can perform only the narrow task it was given.
And in order for the machine to perform the task more effectively, this required a continuous improvement by the human, who needed to update the software, adding lines of codes, to make the machine more efficient for the task.
The new paradigm
In the new paradigm, as Geoffrey Hinton explains:
The new way is you tell the computer to pretend to be in your network with a learning algorithm in it that’s programming but then after that if you want to solve a particular problem you just show examples.
That’s the essence of deep learning.
One example, Geoffrey Hinton explains, is that of having the machine recognize an image:
So suppose you want to solve the problem of I give you all the pixels in the image. That’s three numbers per pixel for the color there’s like let’s say a million of them and you have to turn those three million numbers into a string of words. That says what’s in the image that’s a tricky program to write. People tried for 50 years and didn’t even come close but now a neural net can just do it.
Why is this so important?
Well, because it doesn’t matter, anymore, whether the human is able to write a program to recognize the image.
Because the machine, leveraging a neural net, can solve the problem.
How come they could not solve this problem for 50 years and then they did?
The radical change was in the use of artificial neurons, able to weigh in the inputs received, and produce as an output a non-linear function (able to translate linear inputs, into non-linear outputs) which turned out to be pretty effective for more complex tasks.
A key element to these deep networks is a particular non-linear function, called the activation function.
Today, machine learning models like OpenAI’s GPT-3, Google’s BERT, and DeepMind’s Gato are all deep neural networks.
Those use a particulate architecture, called transformer-based.
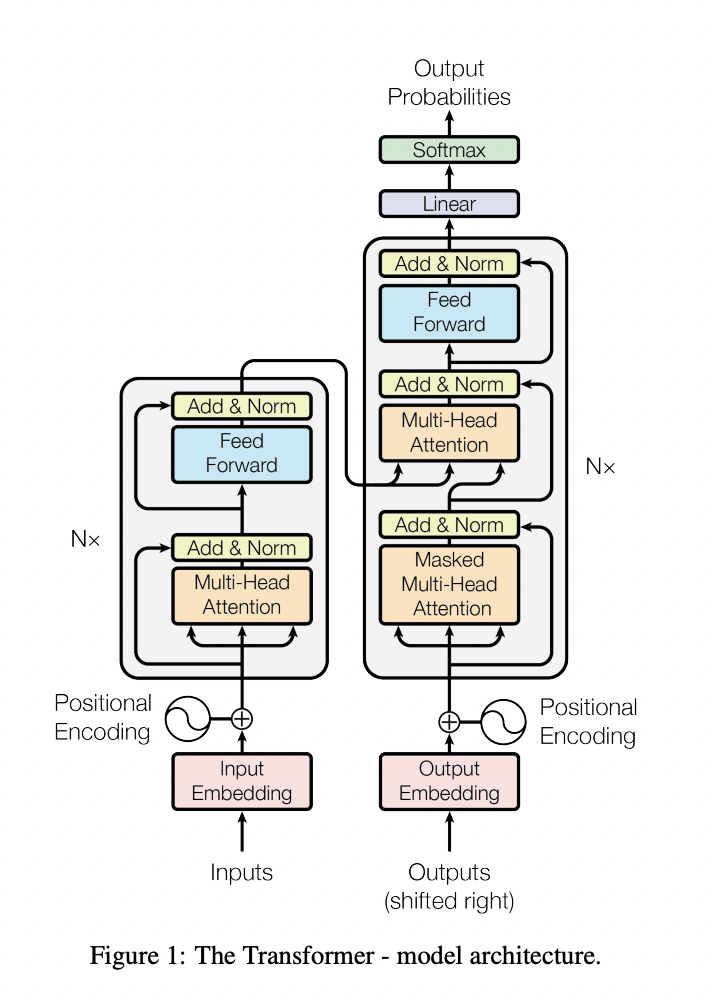
In fact, in a 2017 paper, entitled “Attention Is All You Need” (that’s because a mechanism called “attention mechanism” is the trigger of neurons within the neural network, which cascades into the whole model).
They presented this new, incredible architecture, for a deep learning model, called transformer-based, which opened up the whole AI industry, especially in the field of natural language processing, computer vision, self-driving, and a few other domains.
As we’ll see this architecture has generated such powerful machine learning models that some have gone to the extent of imagining a so-called AGI (artificial general intelligence).
Or the ability of machines to flexibly learn many tasks, while potentially developing sentience. As we’ll see this is far off from now. For one thing, here, we want to understand what are the implications of those machine learning models to the business world.
We’ll look at the potential and business models that can develop thanks to these machine learning models? We’ll look at both the developer’s ecosystem and the business ecosystem around them.
Let’s give a quick look, at the architecture of these deep neural nets, to understand how they work, at a basic level:
Source: Attention is All You Need, 2017
Since then, Transformers have been the foundation of all the breakthrough models like Google BERT and OpenAI GPT3.
A transformer model is a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence.
Therefore, as NVIDIA explains applications using sequential text, image or video data is a candidate for transformer models.
In a paper, in 2021, researchers from Stanford highlighted how transformer-based models have become foundational models.
Source: On the Opportunities and Risks of Foundation Models
As explained in the same paper:
The story of AI has been one of increasing emergence and homogenization. With the introduction of machine learning, how a task is performed emerges (is inferred automatically) from examples; with deep learning, the high-level features used for prediction emerge; and with foundation models, even advanced functionalities such as in-context learning emerge. At the same time, machine learning homogenizes learning algorithms (e.g., logistic regression), deep learning homogenizes model architectures (e.g., Convolutional Neural Networks), and foundation models homogenizes the model itself (e.g., GPT-3).
The rise of foundational models
The central idea of foundational models and transformer-based architecture came from the idea of transferring “knowledge” (or the ability to solve a task) from one domain to another.
As explained in the same paper:
The idea of transfer learning is to take the “knowledge” learned from one task (e.g., object recognition in images) and apply it to another task (e.g., activity recognition in videos).
In short:
Within deep learning, pretraining is the dominant approach to transfer learning: a model is trained on a surrogate task (often just as a means to an end) and then adapted to the downstream task of interest via fine-tuning
Therefore, we have three core moments for the machine learning model:
Pre-training: to adapt the model from one task to another task (for instance, imagine you have a model that generates product descriptions that make sense for one brand. Now, you want it to generate product descriptions that make sense for another brand. Things like tone of voice, and target audience change. This means, that in order for the model to work on another brand, it needs to be pre-trained).
Testing: to validate the model, and understand how it “behaves” on a wider scale (for instance, it’s one thing to have a model that generates products
And fine-tuning: or making the model better and better for the task at hand, by working both on inputs (data fetched to the model) and output (analysis of the results of the model).
What’s different, this time is the sheer scale of these models.
And scale is possible (as highlighted in the foundational model’s paper) through three core ingredients:
Hardware (transition from CPU to GPU, with companies like NVIDIA betting the farm on chips architecture for AI).
Further development of the transformer model architecture.
And the availability of much more training data.
Different from the past, when the data needed to be labeled, to be used. Modern machine learning models (like Google’s BERT) are able to perform tasks in a self-supervised way and with unlabeled data.
The breakthrough deep learning models (BERT, GPT-3, RoBERTa, BART, T5) are based on self-supervised learning coupled with the transformer architecture.
The basic idea is that a single model could be useful for such a wide range of tasks.
The transformer industry has exploded, with more and more coming to market.
From the homogenization and scale of those models, an interesting feature emerged.
By scaling the parameters available to a model (GPT-3 used 175 billion parameters compared to GPT-2’s 1.5 billion) it enabled in-context learning.
While at the same time, unexpectedly, it made arise prompt, or a natural language description of the task), which can be used to refine the model and make it work on other downstream tasks (a specific task you want to be solved).
Source: On the Opportunities and Risks of Foundation Models
Foundational models are extremely powerful because so far they are versatile. From data, be it labeled and structured, or unlabeled and unstructured, the foundational model can adapt to generate various tasks.
The same model can perform question answering, sentiment analysis, image captioning, object recognition, and instruction following.
To get the idea, OpenAI, has a playground for GPT-3. A single model can be used for a multitude of tasks. From Q&A, to grammar correction, translations, classifications, sentiment analyses and much much more.
In that respect, Prompting (or the ability to make the machine perform a very specific task) in the future will be a critical skill.
Indeed, prompting will be critical to generating art, games, code, and much much more.
It’s the prompt that brings you from input to output.
And the quality of the prompt (the ability to describe the task the machine learning model must perform) determines the quality of the output.
Another example of how AI is getting used to enable anyone to code is GitHub’s AI copilot:
The GitHub AI copilot, suggests code and entire functions in real-time.
We need to start from the foundational layers.
Let’s start by analyzing the whole thing, first from the perspective of the developers, building the models and deploying them to the public.
And then we move to the other hand of the spectrum and look at the business ecosystem around it.
The machine learning model workflow
Source: On the Opportunities and Risks of Foundation Models
The first question to ask, is if a developer wants to build machine learning models from scratch, where’s the right place to start based on the workflow to build a model from scratch?
In that case, there is various machine learning software that AI developers can leverage.
In that sense, it’s critical to understand what’s a workflow to build a machine learning model, and the various components the developer will need.
In general, developers build machine learning models to solve specific tasks.
Let’s take the case of a developer that wants o build a model that can generate product page descriptions for a large e-commerce website.
Data creation. In this phase, the human gathers the data needed for the model to perform specific tasks (for instance, in the case of generating product descriptions you want as much text and data about existing products).
Data curation. This is critical to ensure the quality of the data that goes into the model. And also this is usually mostly human-centered.
Training. This is the part of the custom model creation based on the data gathered and curated.
Adaptation. In this phase, starting from the existing model, we pre-train it, to perform new tasks (think of the case of taking GPT-3, to produce product pages content on a specific site, this requires the model to be pre-trained for that site’s context, in order to generate relevant content).
Deployment. The phase in which the model gets released to the world.
I’d add that in most commercial use cases, before deployment, you usually start with a pilot, which has the purpose of answering a very simple question.
Like, can the model produce product pages that make sense to the human?
In this context, the scale is limited (for instance, you start with the generation of 100-500 max product pages).
And if it works, then you start deploying.
After that, based on what I’ve seen, the next stages are:
Iteration: or making sure the model can improve by giving it more data.
Fine-Tuning: or making sure the model can improve substantially by doing data curation.
Scale: enabling the model, on larger and larger volumes for that specific task.
Based on the above, let’s reconstruct the developers’ ecosystem for AI.
MLOps: Developer’s Ecosystem
Machine Learning Ops (MLOps) describes a suite of best practices that successfully help a business run artificial intelligence. It consists of the skills, workflows, and processes to create, run, and maintain machine learning models to help various operational processes within organizations.
Before we get to the specifics of the developers’ workflow, let’s start with a very simple question.
How do you program a machine learning model? What language do you use?
Below are the most popular programming languages, in 2022, according to GitHub stats:
madnight.github.io/githut/#/pull_requests/2022/1
Does it tell you anything? Python, the most popular programming language is also the most popular AI programming language.
In the list of top programming languages, of course, some are not for AI. But the top three, Python, JavaScript and Java are the most popular for AI programming.
Python is the most popular by far.
Given its simplicity, but also thank s to the fact that it gives programmers a set of libraries to draw from, and its interoperable.
Data creation
The data creation part is a human-centered intense task, which is extremely important because the quality of the underlying data will determine the quality of the output of the model.
Keeping into account that the data is also what trains the model, thus if any bias comes from that model, this is due to the way the data has been selected.
For that matter, usually, a model can be trained either with real-world data or synthetic.
For real-world data, think of the case of how Tesla leverages the billions of miles driven by the Tesla owners, across the world, to improve its self-driving algorithms through its deep learning networks.
Tesla self-driving neural nets leverage the billions of miles, driven by Tesla owners, to improve its self-driving algorithms with each new software release!
When it comes to synthetic data, instead, this is produced via computer simulations or algorithms, in the digital world.
Using Python inside NVIDIA Omniverse, AI programmers can generate data straight from a virtual environment. As this is data, that does not exist in the real world, but it gets generated synthetically, it can be used for pre-training AI models, and it’s indeed called synthetic data.
In general, real-world data vs. synthetic data is a matter of choice. Not all companies have the ability to access a wide range of real-world data.
For instance, companies like Tesla, Apple, or Google with successful hardware devices on the market (Tesla cars, iPhone, Android smartphones) have the ability to gather a massive amount of data, and use it to pre-train their models, and improve AI-based products quickly.
Other companies, might not have this change, thus leveraging synthetic data can be faster, cheaper, and in some cases more privacy oriented.
In fact, the rise of the AI industry has already spurred other adjacent industries, like the synthetic data vendors industry.
ZumoLabs, the Synthetic Data Ecosystem, updated in October 2021
Data curation
Once you got the data, it’s all about curation. Data curation is also time-consuming, and yet critical because it determines the quality of the custom model you’ll build.
Also when it comes to data curation there is a whole industry for that.
Training
For the training part, there are various software for that. Training machine learning models, is the centerpiece of the whole workflow. Indeed, the training enables the models to be customized.
For that matter, cloud infrastructures invested substantially to create tools to enable AI programmers and developers. Some of those tools are open source, some others are proprietary.
In general, AI tools are a critical component for both cloud infrastructures, which can enable developers’ communities, around these tools, and therefore boost their cloud offerings.
In short, the AI tool is the “freemium” that serves to amplify the brand of the cloud provider, while prompting developers to host their models on top of their cloud infrastructures.
Not by chance, the most uset AI tools come from companies like Amazon AWS, Google Cloud, IBM and Microsoft’s Azure.
Releasing an AI tool, either as open source or proprietary, isn’t just philosophical choice, it’s also a business model choice.
Indeed, with an open source approach, the AI tool will be monetized only when the model gets hosted on the same cloud infrastructure, in short, it works as a premium.
This is how the ecosystem of tools, look like, when you’re trying to develop AI tools. All-in-one solutions are developing to make up for the fragmentetion of tooling in the AI ecosystem.
Let’s now analyze, the whole business ecosystem, and how it got organized around these machine learning models.
The AI Business Ecosystem
Cloud business models are all built on top of cloud computing, a concept that took over around 2006 when former Google’s CEO Eric Schmit mentioned it. Most cloud-based business models can be classified as IaaS (Infrastructure as a Service), PaaS (Platform as a Service), or SaaS (Software as a Service). While those models are primarily monetized via subscriptions, they are monetized via pay-as-you-go revenue models and hybrid models (subscriptions + pay-as-you-go).
Chip architecture
With the rise of AI, a few tech players have invested all in making chips for AI. One example is NVIDIA, which has created a whole new category of chips’ architecture, based on GPU, which architecture is well fit for AI, heavy lifting.
NVIDIA is a GPU design company, which develops and sells enterprise chips for industries spacing from gaming, data centers, professional visualizations, and autonomous driving. NVIDIA serves major large corporations as enterprise customers, and it uses a platform strategy where it combines its hardware with software tools to enhance its GPUs’ capabilities.
Other companies like Intel, and Qualcomm also focus on AI chips.
Each of those companies, with a particular emphasis.
For instance, NVIDIA’s AI Chips are proving extremely powerful for gaming, data centers, and professional visualizations.
Yet, self-driving and intelligent machines are also critical areas, that NVIDIA is betting on.
Intel as well massively intested into AI chips, which is among its priorities.
And below, is how each of its chip products is used across various AI-powered industries.
Qualcomm also provides a stack of chips for various use cases.
In general, tech giants have now brought the manufacturing of chips, in-house.
One example is Apple which finally started to produce its own chips, for both its phones and computers.
Google, has followed suit, by designing its own chips for the new generations of Pixel phones.
A new chip, designed for the first time in-house, was built to be a premium system on a chip (SoC).
Source: Google
This chip architecture, Google claims, enables it to further power up its devices with machine learning. For example with live translations from one language to another.
Why are companies investing again in chips?
With the rise of AI, and making anything smart, we live at the intersection of various new industries that are spurring the AI revolution (5G, IoT, machine learning models, libraries, and chip architecture).
As such, chip-making has become, again, a core strategic asset for companies that make hardware for consumers.
The three layers of AI
What makes up an AI Business Model?
In short, we can analyze the structure of an AI business model by looking at four main layers:
OpenAI has built the foundational layer of the AI industry. With large generative models like GPT-3 and DALL-E, OpenAI offers API access to businesses that want to develop applications on top of its foundational models while being able to plug these models into their products and customize these models with proprietary data and additional AI features. On the other hand, OpenAI also released ChatGPT, developing around a freemium model. Microsoft also commercializes opener products through its commercial partnership.
Stability AI is the entity behind Stable Diffusion. Stability makes money from our AI products and from providing AI consulting services to businesses. Stability AI monetizes Stable Diffusion via DreamStudio’s APIs. While it also releases it open-source for anyone to download and use. Stability AI also makes money via enterprise services, where its core development team offers the chance to enterprise customers to service, scale, and customize Stable Diffusion or other large generative models to their needs.
I predict that the formula for the next 10,000 startups is that you take something and you add AI to it. We’re going to repeat that by a million times, and it’s going to be really huge.
What is AI today is mostly deep learning?
Deep learning is a subset of machine learning, which is a subset of AI.
What is Transformer-based architecture, it’s all about attention?
The real turning point, for the AI industry, came in 2017. Since the early 2000s, the AI world was living a renaissance, thanks to deep learning.
What is the machine learning model workflow?
The first question to ask, is if a developer wants to build machine learning models from scratch, where’s the right place to start based on the workflow to build a model from scratch?
What is MLOps: Developer’s Ecosystem?
Before we get to the specifics of the developers’ workflow, let’s start with a very simple question.
What makes up an AI Business Model?
In short, we can analyze the structure of an AI business model by looking at four main layers:
Gennaro is the creator of FourWeekMBA, which reached about four million business people, comprising C-level executives, investors, analysts, product managers, and aspiring digital entrepreneurs in 2022 alone | He is also Director of Sales for a high-tech scaleup in the AI Industry | In 2012, Gennaro earned an International MBA with emphasis on Corporate Finance and Business Strategy.
Scroll to Top
Discover more from FourWeekMBA
Subscribe now to keep reading and get access to the full archive.