Machine Learning Ops (MLOps) describe un conjunto de mejores prácticas que ayudan con éxito a una empresa a ejecutar inteligencia artificial. Consiste en las habilidades, flujos de trabajo y procesos para crear, ejecutar y mantener modelos de aprendizaje automático para ayudar a varios procesos operativos dentro de las organizaciones.
Aspecto
Explicación
Descripción general del concepto
MLOps (Operaciones de aprendizaje automático) es un conjunto de prácticas y técnicas que tienen como objetivo poner en funcionamiento y automatizar el ciclo de vida del aprendizaje automático de un extremo a otro. Combina aspectos de máquina de aprendizaje, Ingeniería de softwarey DevOps para agilizar el desarrollo, implementación, monitoreo y mantenimiento de modelos de aprendizaje automático en producción. MLOps garantiza que los proyectos de aprendizaje automático sean escalables, mantenibles y confiables.
Principios fundamentales
MLOps se guía por varios principios clave: 1. Automatización: automatice tareas repetitivas en el proceso de aprendizaje automático, como el preprocesamiento de datos, el entrenamiento de modelos y la implementación. 2. Colaboración: Fomente la colaboración entre científicos de datos, ingenieros y equipos de operaciones para garantizar una integración fluida de los modelos de aprendizaje automático en la producción. 3. Reproducibilidad: Mantenga un registro de todos los experimentos, códigos y datos para permitir la reproducibilidad del modelo y el control de versiones. 4. Integración e implementación continuas (CI/CD): Implementar canales de CI/CD para pruebas e implementación de modelos. 5. Monitoreo y Gobernanza: Supervise continuamente el rendimiento del modelo, la deriva y el cumplimiento de las regulaciones. 6. escalabilidad: Diseñar sistemas que puedan manejar mayores cargas de trabajo a medida que crece la adopción del aprendizaje automático.
Ciclo de vida de MLOps
El ciclo de vida de MLOps normalmente implica las siguientes etapas: 1. Adquisición y preparación de datos: recopile y preprocese datos para el entrenamiento de modelos. 2. Desarrollo de modelos: cree y experimente con modelos de aprendizaje automático. 3. Entrenamiento modelo: Entrene modelos con los datos preparados. 4. Evaluación del modelo: Evalúe el rendimiento del modelo y seleccione el mejor modelo. 5. Implementación del modelo: implemente el modelo seleccionado en un entorno de producción. 6. Monitoreo y mantenimiento del modelo: Supervise continuamente el rendimiento del modelo y vuelva a capacitarlo según sea necesario. 7. Gobernanza y cumplimiento del modelo: Garantizar que los modelos cumplan con los requisitos éticos, legales y reglamentarios.
Beneficios
La implementación de MLOps ofrece varios beneficios: 1. Eficiencia incrementada: Los procesos optimizados reducen los tiempos de desarrollo e implementación. 2. Fiabilidad mejorada del modelo: El monitoreo continuo y las pruebas automatizadas detectan los problemas de manera temprana. 3. Colaboración: Los equipos multifuncionales colaboran de forma más eficaz. 4. escalabilidad: Los sistemas escalables se adaptan a las crecientes cargas de trabajo de aprendizaje automático. 5. Reproducibilidad: Fácil replicación de experimentos y modelos. 6. Rentabilidad: La reducción de la intervención manual reduce los costos operativos.
Desafíos y Riesgos
Los desafíos al adoptar MLOps incluyen la complejidad de integrar el aprendizaje automático con la infraestructura existente, la necesidad de habilidades especializadas y el potencial de privacidad de los datos y preocupaciones éticas, particularmente en las aplicaciones de IA.
Aplicaciones
MLOps se aplica principalmente en campos donde los modelos de aprendizaje automático son fundamentales, incluidos análisis predictivo, procesamiento natural del lenguaje, visión de computadoray sistemas de recomendación. Se utiliza en industrias como financiar, la salud, comercio electrónicoy Fabricación.
Herramientas y tecnologias
Varias herramientas y tecnologías respaldan MLOps, incluidas Docker y Kubernetes para contenerización y orquestación, Jenkins, GitLab CI / CDy Travis CI para canalizaciones de CI/CD y plataformas MLOps especializadas como flujo ml, Kubeflowy TFX (TensorFlow extendido).
Comprender las operaciones de aprendizaje automático
Machine Learning Ops es un concepto relativamente nuevo porque la aplicación comercial de la inteligencia artificial (IA) también es un proceso emergente.
De hecho, la IA irrumpió en escena hace menos de una década después de que un investigador la empleara para ganar un concurso de reconocimiento de imágenes.
Desde ese momento, la inteligencia artificial se puede ver en:
Traducción de sitios web a diferentes idiomas.
Cálculo del riesgo de crédito para solicitudes de hipotecas o préstamos.
Redirección de las llamadas de atención al cliente al departamento correspondiente.
Asistir al personal del hospital en el análisis de rayos X.
Racionalización de las operaciones logísticas y de la cadena de suministro de los supermercados.
Automatización de la generación de texto para atención al cliente, SEO y redacción.
A medida que la IA se vuelve más omnipresente, también debe hacerlo el aprendizaje automático que la impulsa. MLOps se creó en respuesta a la necesidad de que las empresas siguieran un marco de aprendizaje automático desarrollado.
Basado en las prácticas de DevOps, MLOps busca abordar una desconexión fundamental entre el código cuidadosamente elaborado y los datos impredecibles del mundo real. Esta desconexión puede generar problemas como una implementación lenta o inconsistente, baja reproducibilidad y una reducción en el rendimiento.
Los cuatro principios rectores de Machine Learning Ops
Como se señaló, MLOps no es una solución técnica única, sino un conjunto de mejores prácticas o principios rectores.
A continuación se muestra un vistazo a cada uno sin ningún orden en particular:
El aprendizaje automático debe ser reproducible
Es decir, los datos deben poder auditar, verificar y reproducir cada producción. modelo.
El control de versiones para el código en el desarrollo de software es estándar.
Pero en el aprendizaje automático, los datos, los parámetros y los metadatos deben estar todos versionados.
Almacenando modelo artefactos de entrenamiento, el modelo también se puede reproducir si es necesario.
El aprendizaje automático debe ser colaborativo
MLOps defiende que el aprendizaje automático modelo la producción es visible y colaborativa.
Todo, desde la extracción de datos hasta modelo la implementación debe abordarse transformando el conocimiento tácito en código.
El aprendizaje automático debe probarse y monitorearse
Dado que el aprendizaje automático es una práctica de ingeniería, no se deben descuidar las pruebas y la supervisión.
El rendimiento en el contexto de MLOps incorpora importancia predictiva, así como el rendimiento técnico.
Se deben establecer estándares de adhesión modelo y se debe hacer visible el comportamiento esperado.
El equipo no debe confiar en los instintos.
El aprendizaje automático debe ser continuo
Es importante darse cuenta de que un modelo de aprendizaje automático es temporal y cuyo ciclo de vida depende del caso de uso y cuán dinámicos son los datos subyacentes.
Si bien un sistema completamente automatizado puede disminuir con el tiempo, el aprendizaje automático debe verse como un proceso continuo en el que la capacitación se hace lo más fácil posible.
Implementación de MLOps en las operaciones comerciales
En un sentido muy amplio, las empresas pueden implementar MLOps siguiendo unos pocos pasos:
Paso 1: reconocer a las partes interesadas
Los proyectos MLOps suelen ser iniciativas grandes, complejas y multidisciplinarias que requieren las contribuciones de diferentes partes interesadas.
Estos incluyen partes interesadas obvias, como ingenieros de aprendizaje automático, científicos de datos e ingenieros de DevOps.
Sin embargo, estos proyectos también requerirán la colaboración y cooperación de los ingenieros de TI, administración y datos.
Paso 2: invertir en infraestructura
Hay una gran cantidad de productos de infraestructura en el mercado, y no todos nacen iguales.
Al decidir qué producto adoptar, una empresa debe considerar:
Reproducibilidad
El producto debe facilitar la retención del conocimiento de la ciencia de datos.
De hecho, la facilidad de reproducibilidad se rige por el control de versiones de datos y el seguimiento de experimentos.
Eficiencia
¿El producto genera ahorros de tiempo o costos? Por ejemplo, ¿puede el aprendizaje automático eliminar el trabajo manual para aumentar la capacidad de canalización?
Integrabilidad
¿Se integrará bien el producto con los procesos o sistemas existentes?
Paso 3 – Automatización
Antes de pasar a producción, los proyectos de aprendizaje automático deben dividirse en componentes más pequeños y manejables.
Estos componentes deben estar relacionados pero poder desarrollarse por separado.
El proceso de separar un problema en varios componentes obliga al equipo de producto a seguir un proceso conjunto.
Esto fomenta la formación de un lenguaje bien definido entre ingenieros y científicos de datos, que trabajan en colaboración para crear un producto capaz de actualizarse automáticamente.
Esta capacidad es similar a la práctica DevOps de integración continua (CI).
MLOps y AIaaS
La inteligencia artificial como servicio (AlaaS) ayuda a las organizaciones a incorporar la funcionalidad de inteligencia artificial (IA) sin la experiencia asociada. Por lo general, los servicios AIaaS se basan en proveedores basados en la nube como Amazon AWS, Google Cloud, Microsoft Azure e IMB Cloud, que se utilizan como IaaS. El servicio, el marco y los flujos de trabajo de IA basados en estas infraestructuras se ofrecen a los clientes finales para varios casos de uso (por ejemplo, inventario servicios de gestión, optimizaciones de fabricación, generación de textos).Fuente: cloud.google.com
MLOps consta de varias fases construidas sobre una plataforma de IA, donde los modelos deberán prepararse (a través del etiquetado de datos, conjuntos de datos de Big Query y almacenamiento en la nube), construirse, validarse e implementarse.
Y MLOps es un mundo vasto, hecho de muchas partes móviles.
De hecho, antes de que se pueda operar el código ML, como se destaca en Google Cloud, se gasta mucho en “configuración, automatización, recopilación de datos, verificación de datos, pruebas y depuración, gestión de recursos, modelo análisis, gestión de procesos y metadatos, infraestructura de servicio y monitoreo”.
El proceso de aprendizaje automático
Los modelos de ML siguen varios pasos, un ejemplo es: Extracción de datos > Datos análisis > Preparación de datos > Entrenamiento de modelos > Evaluación de modelos > Validación de modelos > Servicio de modelos > Supervisión de modelos.
Ejemplos de operaciones de aprendizaje automático
A continuación se muestran algunos ejemplos de cómo se aplican las operaciones de aprendizaje automático en empresas como Uber y Booking.com.
Uber es un mercado de dos caras, una plataforma modelo de negocio que conecta a los conductores y pasajeros, con una interfaz que tiene elementos de gamificación, que facilita la conexión y la transacción de dos lados. Uber gana dinero recaudando tarifas de las reservas brutas de la plataforma.
Uber Michelangelo es el nombre que recibe el aprendizaje automático de Uber plataforma que estandariza el flujo de trabajo entre equipos y mejora la coordinación.
Antes de que se desarrollara Michelangelo, Uber enfrentaba dificultades para implementar modelos de aprendizaje automático debido al gran tamaño de la empresa y sus operaciones.
Mientras los científicos de datos desarrollaban modelos predictivos, los ingenieros también creaban sistemas únicos y personalizados que utilizaban estos modelos en la producción.
En última instancia, el impacto del aprendizaje automático en Uber se limitó a lo que los científicos e ingenieros pudieran construir en un corto período de tiempo con herramientas predominantemente de código abierto.
Michelangelo se concibió para proporcionar un sistema en el que se pudieran construir canalizaciones fiables, uniformes y reproducibles para la creación y gestión de datos de predicción y entrenamiento a escala.
Hoy, los MLOps plataforma estandariza los flujos de trabajo y los procesos a través de un sistema de extremo a extremo donde los usuarios pueden construir y operar fácilmente sistemas ML.
Si bien Michelangelo administra docenas de modelos en toda la empresa para innumerables casos de uso, su aplicación para UberEATS vale la pena una mención rápida.
Uber Eats es un mercado de tres lados que conecta a un conductor, un dueño de restaurante y un cliente con Uber Eats plataforma en el centro. El mercado de tres lados se mueve alrededor de tres jugadores: los restaurantes pagan una comisión por los pedidos a Uber Eats; Los clientes pagan los pequeños gastos de envío y, en ocasiones, los gastos de cancelación; Los conductores ganan al hacer entregas confiables a tiempo.
Aquí, el aprendizaje automático se incorporó en las predicciones de tiempo de entrega de comidas, clasificaciones de restaurantes, clasificaciones de búsqueda y autocompletado de búsqueda.
Calcular el tiempo de entrega de la comida se considera particularmente complejo e involucra muchas partes móviles, con Michelangelo usando modelos de regresión de árbol para hacer estimaciones de entrega de extremo a extremo basadas en múltiples métricas actuales e históricas.
Booking.com es el sitio web de agencias de viajes en línea más grande del mundo, con usuarios que pueden buscar millones de opciones de alojamiento diferentes.
Al igual que Uber, Booking.com necesitaba una solución compleja de aprendizaje automático que pudiera implementarse a escala.
Para comprender la situación de la empresa, imaginemos a un usuario que busca alojamiento en París.
En el momento de escribir este artículo, hay más de 4,700 establecimientos, pero sería poco realista esperar que el usuario los vea todos.
En un nivel un tanto básico, los algoritmos de aprendizaje automático enumeran los hoteles en función de entradas como la ubicación, la calificación de revisión, el precio y las comodidades.
Los algoritmos también consideran los datos disponibles sobre el usuario, como su propensión a reservar ciertos tipos de alojamiento y si el viaje es por negocios o por placer.
Se utiliza un aprendizaje automático más complejo para evitar la plataforma sirviendo resultados que consisten en hoteles similares.
Sería imprudente que Booking.com enumerara 10 hoteles parisinos de 3 estrellas al mismo precio en la primera página de los resultados.
Para contrarrestar esto, el aprendizaje automático incorpora aspectos de la economía del comportamiento, como la compensación entre exploración y explotación.
El algoritmo también recopilará datos sobre el usuario mientras busca un lugar para quedarse.
Tal vez pasen más tiempo buscando hoteles familiares con piscina, o tal vez prefieran un bed and breakfast cerca de la Torre Eiffel.
Un aspecto importante, pero que a veces se pasa por alto, del sitio web de Booking.com son los propietarios y anfitriones del alojamiento.
Este grupo de usuarios tiene su propio conjunto de intereses que a veces entran en conflicto con los turistas y la propia empresa.
En el caso de este último, el aprendizaje automático jugará un papel cada vez más importante en la relación de Booking.com con sus proveedores y, por extensión, en su viabilidad a largo plazo.
Booking.com hoy es la culminación de 150 aplicaciones exitosas de aprendizaje automático centradas en el cliente desarrolladas por docenas de equipos en toda la empresa.
Estos fueron expuestos a cientos de millones de usuarios y validados a través de ensayos aleatorios pero controlados.
La empresa llegó a la conclusión de que el proceso iterativo basado en hipótesis que buscó inspiración en otras disciplinas fue clave para el éxito de la iniciativa.
Puntos clave
Machine Learning Ops abarca un conjunto de mejores prácticas que ayudan a las organizaciones a incorporar con éxito la inteligencia artificial.
Machine Learning Ops busca abordar la desconexión entre el código cuidadosamente escrito y los datos impredecibles del mundo real. Al hacerlo, MLOps puede mejorar la eficiencia de los ciclos de lanzamiento de aprendizaje automático.
La implementación de Machine Learning Ops puede ser compleja y, como resultado, depende de los aportes de muchas partes interesadas diferentes. Invertir en la infraestructura adecuada y centrarse en la automatización también es crucial.
Aspectos destacados de Machine Learning Ops (MLOps):
Definición: Machine Learning Ops (MLOps) abarca las mejores prácticas para ejecutar de manera efectiva la inteligencia artificial en las operaciones comerciales, incluidas las habilidades, los flujos de trabajo y los procesos para crear, administrar y mantener modelos de aprendizaje automático.
Aparición: MLOps es relativamente nuevo debido a la adopción comercial de la inteligencia artificial, que surgió hace menos de una década con aplicaciones como el reconocimiento de imágenes.
Aplicaciones: AI ahora se usa ampliamente en varios campos, incluida la traducción de idiomas, la evaluación de riesgos crediticios, el servicio al cliente, la atención médica, la logística y más.
Desafios: MLOps surgió para abordar desafíos como la implementación lenta, la baja reproducibilidad y el rendimiento inconsistente causado por la desconexión entre el código y los datos del mundo real.
Principios rectores:
Reproducibilidad: Capacidad para auditar, verificar y reproducir modelos de producción mediante el control de versiones de datos, parámetros y metadatos.
Colaboración: promueve la visibilidad y la colaboración en la producción de modelos de aprendizaje automático mediante la transformación del conocimiento tácito en código.
Pruebas y seguimiento: enfatiza las pruebas, el monitoreo y el establecimiento de estándares de cumplimiento del modelo tanto para la importancia predictiva como para el rendimiento técnico.
Mejora continua: Trata el aprendizaje automático como un proceso continuo, acomodando el reciclaje según sea necesario.
Pasos para la implementación:
Reconocer a las partes interesadas: Involucrar a varias partes interesadas, incluidos ingenieros de aprendizaje automático, científicos de datos, ingenieros de DevOps, TI, administración e ingenieros de datos.
Invertir en Infraestructura: Elija productos de infraestructura en función de la reproducibilidad, la eficiencia y la integrabilidad.
Automatización : Divida los proyectos de aprendizaje automático en componentes manejables, fomentando la colaboración y habilitando actualizaciones automáticas.
IA como servicio (AIaaS): AI as a Service ofrece funcionalidades de IA a las organizaciones sin necesidad de experiencia interna en IA. Utiliza plataformas basadas en la nube (por ejemplo, Amazon AWS, Google Cloud, Microsoft Azure) y ofrece varios servicios para diferentes casos de uso.
Fases de MLOps: MLOps implica fases como la preparación, construcción, validación e implementación del modelo sobre una plataforma de IA.
Aprendizaje automático en Uber y Booking.com:
Uber: Michelangelo es el aprendizaje automático de Uber plataforma que estandariza los flujos de trabajo, coordina los esfuerzos y administra los modelos en varios casos de uso.
Booking.com: utiliza el aprendizaje automático para recomendar alojamientos en función de factores como la ubicación, el precio y el comportamiento del usuario, lo que mejora la experiencia del usuario y las relaciones con los anfitriones.
Conclusión clave: MLOps es un conjunto de prácticas que garantiza la integración eficiente de la inteligencia artificial en las operaciones comerciales. Aborda los desafíos relacionados con la implementación, la gestión y la mejora de los modelos de aprendizaje automático, lo que permite a las organizaciones beneficiarse de la IA de manera eficaz.
Conceptos relacionados
Descripción
Cuando aplicar
MLOps (Operaciones de aprendizaje automático)
MLOps (Operaciones de aprendizaje automático) es un conjunto de prácticas y principios que tienen como objetivo optimizar y automatizar el ciclo de vida de un extremo a otro de los modelos de aprendizaje automático (ML), desde el desarrollo y la capacitación hasta la implementación y el monitoreo en entornos de producción. MLOps integra ingeniería de software, ingeniería de datos y metodologías DevOps para permitir flujos de trabajo de aprendizaje automático escalables, confiables y reproducibles, abordando desafíos relacionados con el control de versiones de modelos, la reproducibilidad, la escalabilidad y el monitoreo del rendimiento. MLOps enfatiza la colaboración, la automatización y la mejora continua entre equipos multifuncionales involucrados en proyectos de ML, lo que facilita el desarrollo, la implementación y el mantenimiento eficientes de modelos a escala.
- Cuando operacionalizar modelos de aprendizaje automático or implementar soluciones de IA en entornos de producción. – Particularmente en situaciones en las que es necesario optimizar los flujos de trabajo de ML, garantizar la escalabilidad y confiabilidad del modelo o mejorar la colaboración entre científicos de datos, ingenieros y equipos de operaciones. La implementación de prácticas MLOps permite a las organizaciones acelerar la implementación del modelo ML, automatizar el monitoreo del modelo y optimizar el rendimiento del modelo en aplicaciones del mundo real, impulsando el valor comercial y la innovación en iniciativas impulsadas por IA.
DevOps
DevOps es una metodología de desarrollo de software y un enfoque cultural que enfatiza la colaboración, la automatización y la integración entre los equipos de desarrollo (Dev) y operaciones (Ops) para mejorar la velocidad, la calidad y la eficiencia de la entrega e implementación de software. Las prácticas de DevOps incluyen integración continua (CI), entrega continua (CD), infraestructura como código (IaC) y pruebas automatizadas, lo que permite a las organizaciones automatizar los procesos de desarrollo de software, implementar cambios con mayor frecuencia y mejorar los ciclos de retroalimentación entre los equipos de desarrollo y operaciones. DevOps fomenta una cultura de colaboración, transparencia y mejora continua, impulsando agilidad, innovación y resiliencia en los procesos de desarrollo e implementación de software.
- Cuando agilizar el desarrollo de software y procesos de despliegue para mejorar la agilidad y la fiabilidad. – Particularmente en situaciones en las que es necesario acelerar la entrega de software, mejorar la colaboración entre los equipos de desarrollo y operaciones, o automatizar el aprovisionamiento y la implementación de infraestructura. La adopción de prácticas de DevOps permite a las organizaciones optimizar los ciclos de vida de desarrollo de software, reducir el tiempo de comercialización y mejorar la calidad y confiabilidad del software en el desarrollo de aplicaciones, operaciones de TI e iniciativas de transformación digital.
Integración continua (CI)
Integración continua (CI) es una práctica de desarrollo de software que implica la integración frecuente de cambios de código de múltiples desarrolladores en un repositorio compartido, seguido de procesos automatizados de compilación y prueba para detectar errores de integración tempranamente y garantizar la calidad y estabilidad del código. CI tiene como objetivo mejorar la colaboración, reducir los riesgos de integración y acelerar los ciclos de desarrollo de software mediante la automatización del proceso de integración, compilación y prueba de código en un entorno controlado. Los sistemas de CI activan automáticamente procesos de compilación y prueba cada vez que se envían cambios de código al repositorio de control de versiones, proporcionando retroalimentación rápida a los desarrolladores y facilitando la detección temprana y la resolución de problemas de integración.
- Cuando integración de código automatizada y procesos de prueba para mejorar la calidad del software y la velocidad de desarrollo. – Especialmente en situaciones en las que hay varios desarrolladores trabajando en la misma base de código o en las que es necesario detectar errores de integración en las primeras etapas del ciclo de vida del desarrollo. La implementación de la integración continua permite a las organizaciones optimizar los flujos de trabajo de desarrollo, mejorar la colaboración entre los equipos de desarrollo y ofrecer software de alta calidad con mayor velocidad y eficiencia en el desarrollo de software, DevOps y metodologías ágiles.
Despliegue continuo (CD)
Despliegue continuo (CD) es una extensión de integración continua (CI) que automatiza el proceso de implementación de cambios de código en entornos de producción una vez que pasan pruebas automatizadas y controles de calidad. CD tiene como objetivo acelerar aún más los ciclos de entrega de software, reducir la intervención manual y mejorar la confiabilidad y repetibilidad de la implementación mediante la automatización del proceso de implementación desde el desarrollo hasta la producción. Los sistemas de CD publican automáticamente cambios de software en entornos de producción después de pruebas exitosas, lo que permite a las organizaciones ofrecer nuevas funciones, actualizaciones y correcciones a los usuarios de manera rápida y confiable. CD enfatiza los mecanismos de automatización, monitoreo y reversión para garantizar una implementación segura y fluida de los cambios en los entornos de producción.
- Cuando automatización de la implementación de software procesos a agilizar los ciclos de lanzamiento y mejorar la confiabilidad de la implementación. – Particularmente en situaciones en las que es necesario acelerar el tiempo de comercialización, reducir los errores de implementación o garantizar la entrega consistente de cambios de software. La implementación de la implementación continua permite a las organizaciones automatizar los procesos de implementación, reducir la intervención manual y entregar actualizaciones de software a entornos de producción de manera rápida y confiable en iniciativas de desarrollo de software, DevOps y computación en la nube.
Despliegue del modelo
Despliegue del modelo se refiere al proceso de implementar modelos de aprendizaje automático (ML) en entornos de producción donde pueden hacer predicciones o realizar tareas basadas en nuevas entradas de datos. La implementación de modelos implica empaquetar modelos de ML entrenados junto con las dependencias asociadas e implementarlos en una infraestructura de producción escalable y confiable, como plataformas en la nube o entornos en contenedores. La implementación de modelos garantiza que los modelos de aprendizaje automático estén disponibles para su inferencia o uso por parte de los usuarios finales o aplicaciones posteriores, lo que permite a las organizaciones obtener información, tomar decisiones o automatizar tareas basadas en análisis predictivos o algoritmos de aprendizaje automático. La implementación del modelo abarca consideraciones como escalabilidad, confiabilidad, latencia, seguridad y monitoreo para garantizar que los modelos implementados funcionen de manera efectiva y cumplan con los requisitos comerciales en aplicaciones del mundo real.
- Cuando operacionalizar modelos de aprendizaje automático para uso del mundo real en entornos de producción. – Particularmente en situaciones en las que es necesario implementar modelos de ML entrenados para hacer predicciones, automatizar tareas o respaldar procesos de toma de decisiones. La implementación de modelos permite a las organizaciones aprovechar las capacidades de aprendizaje automático, obtener información procesable e impulsar el valor empresarial a través de análisis predictivos, sistemas de recomendación o automatización inteligente en iniciativas impulsadas por IA y aplicaciones basadas en datos.
Monitoreo de modelos
Monitoreo de modelos es el proceso de seguimiento y evaluación continua del rendimiento, el comportamiento y la calidad de los modelos de aprendizaje automático (ML) implementados en entornos de producción para garantizar que funcionen según lo previsto y proporcionen predicciones o resultados confiables. El monitoreo de modelos implica recopilar y analizar datos sobre las entradas, salidas, predicciones y retroalimentación del modelo a lo largo del tiempo, detectar desviaciones, desviaciones o anomalías en el comportamiento del modelo y activar alertas o acciones para abordar problemas o mantener el rendimiento del modelo. El monitoreo de modelos permite a las organizaciones identificar y mitigar problemas como la deriva de conceptos, problemas de calidad de los datos o degradación del modelo que pueden afectar la precisión, equidad o efectividad de los modelos de ML implementados en aplicaciones del mundo real.
- Cuando monitorear el desempeño y comportamiento de los modelos ML implementados in entornos de producción. – Particularmente en situaciones en las que es necesario garantizar que los modelos implementados funcionen de manera confiable, funcionen de manera efectiva y brinden predicciones o resultados precisos a lo largo del tiempo. La implementación del monitoreo de modelos permite a las organizaciones detectar y abordar problemas o anomalías en el comportamiento del modelo, mantener el rendimiento del modelo y garantizar el cumplimiento de los requisitos comerciales y los estándares regulatorios en iniciativas impulsadas por IA y aplicaciones basadas en datos.
Control de versiones del modelo
Control de versiones del modelo es la práctica de gestionar y rastrear sistemáticamente diferentes versiones o iteraciones de modelos de aprendizaje automático (ML) a lo largo de su ciclo de vida, desde el desarrollo y la capacitación hasta la implementación y el mantenimiento. El control de versiones del modelo implica capturar metadatos, código, configuraciones y dependencias asociadas con cada versión del modelo, lo que permite la reproducibilidad, la trazabilidad y la responsabilidad en los flujos de trabajo de ML. El control de versiones de modelos facilita la colaboración, la experimentación y la gobernanza en proyectos de aprendizaje automático al proporcionar un marco estructurado para gestionar cambios, comparaciones e implementaciones de modelos en diferentes entornos y partes interesadas. Los sistemas de control de versiones de modelos se integran con herramientas y plataformas de control de versiones para garantizar la coherencia, integridad y visibilidad de los artefactos y artefactos del modelo de aprendizaje automático y agilizar los procesos de desarrollo, implementación y mantenimiento de modelos.
- Cuando gestionar cambios y iteraciones de modelos de aprendizaje automático a lo largo de su ciclo de vida. – Particularmente en situaciones en las que hay múltiples iteraciones o versiones de modelos de ML, o donde es necesario realizar un seguimiento de los cambios, comparaciones o implementaciones del modelo en diferentes entornos o partes interesadas. La implementación del control de versiones de modelos permite a las organizaciones mantener la integridad del modelo, facilitar la colaboración y garantizar la reproducibilidad y trazabilidad en los flujos de trabajo de aprendizaje automático, mejorando la transparencia y la gobernanza en iniciativas impulsadas por IA y proyectos de ciencia de datos.
Gobernanza modelo
Gobernanza modelo se refiere a las políticas, procesos y controles establecidos por las organizaciones para garantizar el desarrollo, implementación y gestión responsable de los modelos de aprendizaje automático (ML) a lo largo de su ciclo de vida. La gobernanza del modelo abarca consideraciones como ética, equidad, transparencia, responsabilidad y cumplimiento normativo en proyectos de aprendizaje automático, abordando riesgos relacionados con prejuicios, privacidad, seguridad e implicaciones legales. Los marcos de gobernanza modelo definen roles y responsabilidades, establecen directrices y estándares e implementan controles y mecanismos de supervisión para mitigar riesgos, fomentar la confianza y garantizar el uso ético y responsable de las tecnologías de aprendizaje automático en aplicaciones del mundo real. La gobernanza del modelo tiene como objetivo alinear las iniciativas de ML con los valores organizacionales, los requisitos regulatorios y las expectativas sociales, promoviendo la transparencia, la equidad y la responsabilidad en los procesos de toma de decisiones impulsados por la IA.
- Cuando estableciendo políticas y controles Para asegurar la uso responsable y Management de modelos de aprendizaje automático. – Particularmente en situaciones donde existen consideraciones éticas, legales o regulatorias en los proyectos de ML, o donde existe la necesidad de mitigar los riesgos relacionados con el sesgo, la equidad o la privacidad. La implementación de un modelo de gobernanza permite a las organizaciones establecer confianza, garantizar el cumplimiento y mitigar los riesgos asociados con las tecnologías de aprendizaje automático, fomentando la adopción responsable de la IA y promoviendo prácticas éticas y responsables en iniciativas impulsadas por la IA y proyectos de ciencia de datos.
Explicabilidad del modelo
Explicabilidad del modelo es la capacidad de interpretar y comprender las decisiones y predicciones realizadas por los modelos de aprendizaje automático (ML), proporcionando información sobre los factores, características o patrones que influyen en los resultados del modelo. Las técnicas de explicabilidad de modelos tienen como objetivo descubrir los mecanismos internos y los procesos de toma de decisiones de los modelos de ML, permitiendo a los usuarios interpretar predicciones de modelos, evaluar el comportamiento del modelo e identificar factores que contribuyen al rendimiento del modelo. La explicabilidad del modelo mejora la transparencia, la confianza y la responsabilidad en los modelos de ML al hacerlos más interpretables y comprensibles para las partes interesadas, como expertos en el dominio, reguladores o usuarios finales. Los métodos de IA explicable (XAI) incluyen análisis de importancia de características, técnicas de interpretación de modelos y enfoques de explicación post-hoc, que brindan información sobre las predicciones del modelo y permiten a los usuarios validar, depurar o mejorar el rendimiento y la confiabilidad del modelo en aplicaciones del mundo real.
- Cuando interpretar y comprensión las decisiones y predicciones realizado mediante modelos de aprendizaje automático. – Particularmente en situaciones en las que es necesario explicar el comportamiento del modelo, evaluar la confiabilidad del modelo u obtener información sobre los factores que influyen en los resultados del modelo. La implementación de técnicas de explicabilidad de modelos permite a las organizaciones mejorar la transparencia, la confianza y la responsabilidad en los modelos de aprendizaje automático, lo que permite a las partes interesadas comprender y validar las predicciones y decisiones de los modelos en iniciativas impulsadas por IA y proyectos de ciencia de datos.
Sesgo y equidad del modelo
Sesgo y equidad del modelo se refiere a la evaluación y mitigación de sesgos e injusticias en los modelos de aprendizaje automático (ML), asegurando que los modelos hagan predicciones o decisiones que sean equitativas, imparciales y no discriminatorias entre diferentes grupos demográficos o características protegidas. Las consideraciones de equidad y sesgo del modelo abordan cuestiones como el sesgo algorítmico, el sesgo de datos y las disparidades de equidad que pueden generar resultados discriminatorios o perpetuar las desigualdades sociales en las aplicaciones de ML. Las técnicas para evaluar y mitigar el sesgo y la equidad del modelo incluyen algoritmos conscientes de la equidad, métodos de detección de sesgos e intervenciones de equidad, que tienen como objetivo identificar, medir y mitigar los sesgos en los datos de entrenamiento, los resultados del modelo y los procesos de toma de decisiones. Las evaluaciones de sesgo y equidad de los modelos ayudan a las organizaciones a identificar y abordar los riesgos éticos y sociales asociados con los modelos de aprendizaje automático, promover la equidad y la inclusión y garantizar resultados equitativos en la toma de decisiones impulsada por la IA y los sistemas automatizados.
- Cuando evaluar y mitigar sesgos y disparidades de equidad en modelos de aprendizaje automático. – Particularmente en situaciones donde existen implicaciones éticas, legales o sociales de predicciones o decisiones de modelos sesgadas o injustas. Abordar el sesgo y la equidad del modelo permite a las organizaciones promover prácticas éticas de IA, mitigar los riesgos de discriminación y garantizar resultados equitativos en las iniciativas y procesos de toma de decisiones impulsados por la IA, fomentando la confianza y la inclusión en las aplicaciones de IA y los sistemas basados en datos.
AIOps es la aplicación de la inteligencia artificial a las operaciones de TI. Se ha vuelto particularmente útil para la administración de TI moderna en entornos híbridos, distribuidos y dinámicos. AIOps se ha convertido en un componente operativo clave de las organizaciones digitales modernas, construido en torno a software y algoritmos.
Agile comenzó como un método de desarrollo liviano en comparación con el desarrollo de software pesado, que es el paradigma central de las décadas anteriores de desarrollo de software. Para el año 2001 nació el Manifiesto para el Desarrollo Ágil de Software como un conjunto de principios que definieron el nuevo paradigma para el desarrollo de software como una iteración continua. Esto también influiría en la forma de hacer negocios.
Agile Program Management es un medio para administrar, planificar y coordinar el trabajo interrelacionado de tal manera que se enfatiza la entrega de valor para todas las partes interesadas clave. Agile Program Management (AgilePgM) es un enfoque ágil disciplinado pero flexible para gestionar el cambio transformacional dentro de una organización.
La gestión ágil de proyectos (APM) es una estrategia que divide grandes proyectos en tareas más pequeñas y manejables. En la metodología APM, cada proyecto se completa en pequeñas secciones, a menudo denominadas iteraciones. Cada iteración se completa de acuerdo con su ciclo de vida del proyecto, comenzando con el inicial personalizable y progresando a las pruebas y luego al aseguramiento de la calidad.
Agile Modeling (AM) es una metodología para modelar y documentar sistemas basados en software. El modelado ágil es fundamental para la entrega rápida y continua de software. Es una colección de valores, principios y prácticas que guían el modelado de software efectivo y liviano.
Agile Business Analysis (AgileBA) es una certificación en forma de orientación y capacitación para analistas de negocios que buscan trabajar en entornos ágiles. Para respaldar este cambio, AgileBA también ayuda al analista de negocios a relacionar los proyectos ágiles con una organización organizacional más amplia. misión or estrategia. Para garantizar que los analistas tengan las habilidades y la experiencia necesarias, se desarrolló la certificación AgileBA.
El liderazgo ágil es la encarnación de los principios del manifiesto ágil por parte de un gerente o equipo de gestión. El liderazgo ágil impacta en dos niveles importantes de un negocio. El nivel estructural define los roles, responsabilidades e indicadores clave de desempeño. El nivel de comportamiento describe las acciones que los líderes muestran a los demás con base en principios ágiles.
Bimodal Portfolio Management (BimodalPfM) ayuda a una organización a administrar simultáneamente carteras ágiles y tradicionales. La gestión de cartera bimodal, a veces denominada desarrollo bimodal, fue acuñada por la empresa de investigación y asesoramiento Gartner. La firma argumentó que muchas organizaciones ágiles aún necesitaban ejecutar algunos aspectos de sus operaciones utilizando modelos de entrega tradicionales.
Empresa innovación se trata de crear nuevas oportunidades para que una organización reinvente sus ofertas principales, sus fuentes de ingresos y mejore la propuesta de valor para clientes existentes o nuevos, renovando así todo su modelo de negocio. Negocio innovación resortes al comprender la estructura del mercado, adaptándose o anticipándose a esos cambios.
modelo de negocio innovación se trata de aumentar el éxito de una organización con productos y tecnologías existentes mediante la elaboración de un convincente propuesta de valor capaz de impulsar una nueva modelo de negocio para aumentar la escala de los clientes y crear una ventaja competitiva duradera. Y todo comienza dominando a los clientes clave.
Un consumidor marca Una empresa como Procter & Gamble (P&G) define la "disrupción constructiva" como: la voluntad de cambiar, adaptarse y crear nuevas tendencias y tecnologías que darán forma a nuestra industria para el futuro. Según P&G, se mueve en torno a cuatro pilares: lean innovación, marca construcción, cadena de suministro y digitalización y análisis de datos.
Ese es un proceso que requiere un ciclo de retroalimentación continuo para desarrollar un producto valioso y construir un modelo comercial viable. Continuo innovación es una mentalidad en la que los productos y servicios se diseñan y entregan para adaptarlos al problema de los clientes y no a la solución técnica de sus fundadores.
A personalizable sprint es un proceso comprobado de cinco días en el que las preguntas comerciales críticas se responden a través de personalizable y creación de prototipos, centrándose en el usuario final. UN personalizable Sprint comienza con un desafío semanal que debe terminar con un prototipo, una prueba al final y, por lo tanto, una lección aprendida para ser iterada.
Tim Brown, presidente ejecutivo de IDEO, definió personalizable pensamiento como “un enfoque centrado en el ser humano para innovación que se basa en el conjunto de herramientas del diseñador para integrar las necesidades de las personas, las posibilidades de la tecnología y los requisitos para el éxito empresarial”. Por lo tanto, la conveniencia, la factibilidad y la viabilidad se equilibran para resolver problemas críticos.
DevOps se refiere a una serie de prácticas realizadas para realizar procesos de desarrollo de software automatizados. Es una conjugación del término "desarrollo" y "operaciones" para enfatizar cómo las funciones se integran en los equipos de TI. Las estrategias de DevOps promueven la creación, prueba e implementación de productos sin inconvenientes. Su objetivo es cerrar la brecha entre los equipos de desarrollo y operaciones para optimizar el desarrollo por completo.
El descubrimiento de productos es una parte fundamental de las metodologías ágiles, ya que su objetivo es garantizar que se construyan los productos que a los clientes les encantan. El descubrimiento de productos implica aprender a través de una serie de métodos, que incluyen personalizable pensamiento, lean start-up y pruebas A/B, por nombrar algunos. Dual Track Agile es una metodología ágil que contiene dos pistas separadas: la pista de "descubrimiento" y la pista de "entrega".
El desarrollo basado en funciones es un proceso de software pragmático centrado en el cliente y la arquitectura. El desarrollo basado en funciones (FDD) es un modelo de desarrollo de software ágil que organiza el flujo de trabajo según las funciones que deben desarrollarse a continuación.
eXtreme Programming fue desarrollado a fines de la década de 1990 por Ken Beck, Ron Jeffries y Ward Cunningham. Durante este tiempo, el trío estuvo trabajando en el Sistema Integral de Compensación de Chrysler (C3) para ayudar a administrar el sistema de nómina de la empresa. eXtreme Programming (XP) es una metodología de desarrollo de software. Está diseñado para mejorar la calidad del software y la capacidad del software para adaptarse a las necesidades cambiantes de los clientes.
El modelo de puntuación de ICE es una metodología ágil que prioriza características utilizando datos de acuerdo con tres componentes: impacto, confianza y facilidad de implementación. El modelo de puntuación de ICE fue creado inicialmente por el autor y crecimiento experto Sean Ellis para ayudar a las empresas a expandirse. Hoy en día, el modelo se usa ampliamente para priorizar proyectos, características, iniciativas y lanzamientos. Es ideal para el desarrollo de productos en etapa inicial donde hay un flujo continuo de ideas y se debe mantener el impulso.
An innovación funnel es una herramienta o proceso que garantiza que solo se ejecuten las mejores ideas. En un sentido metafórico, el embudo filtra las ideas innovadoras en busca de viabilidad para que solo los mejores productos, procesos o modelos de negocio se lanzan al mercado. Un innovación funnel proporciona un marco para la selección y prueba de viabilidad de ideas innovadoras.
Según lo bien definido que esté el problema y lo bien definido el dominio, tenemos cuatro tipos principales de innovaciones: investigación básica (problema y dominio o no bien definido); descubrimiento innovación (el dominio no está bien definido, el problema está bien definido); nutritivo innovación (tanto el problema como el dominio están bien definidos); y disruptivo innovación (el dominio está bien definido, el problema no está bien definido).
La innovación loop es una metodología/marco derivado de Bell Labs, que produjo innovación a escala a lo largo del siglo XX. Aprendieron a aprovechar un híbrido innovación modelo de gestión basado en la ciencia, la invención, la ingeniería y la fabricación a escala. Aprovechando el genio individual, la creatividad y los grupos pequeños/grandes.
La metodología Agile ha sido pensada principalmente para el desarrollo de software (y otras disciplinas empresariales también la han adoptado). El pensamiento Lean es una técnica de mejora de procesos en la que los equipos priorizan los flujos de valor para mejorarlos continuamente. Ambas metodologías ven al cliente como el motor clave para la mejora y la reducción de desperdicios. Ambas metodologías ven la mejora como algo continuo.
Una empresa nueva es una empresa de alta tecnología que trata de construir una escalable modelo de negocio en industrias impulsadas por la tecnología. Una empresa de nueva creación suele seguir una metodología ajustada, en la que innovación, impulsado por bucles virales incorporados es la regla. Así, conducir crecimiento y edificio efectos de red como consecuencia de esto estrategia.
Kanban es un marco de manufactura esbelta desarrollado por primera vez por Toyota a fines de la década de 1940. El marco Kanban es un medio para visualizar el trabajo a medida que avanza identificando posibles cuellos de botella. Lo hace a través de un proceso llamado fabricación justo a tiempo (JIT) para optimizar los procesos de ingeniería, acelerar la fabricación de productos y mejorar la comercialización. estrategia.
RAD fue presentado por primera vez por el autor y consultor James Martin en 1991. Martin reconoció y luego aprovechó la infinita maleabilidad del software en el diseño de modelos de desarrollo. El desarrollo rápido de aplicaciones (RAD) es una metodología que se enfoca en entregar rápidamente a través de comentarios continuos e iteraciones frecuentes.
Scaled Agile Lean Development (ScALeD) ayuda a las empresas a descubrir un enfoque equilibrado para la transición ágil y las cuestiones de escalado. El enfoque ScALed ayuda a las empresas a responder con éxito al cambio. Inspirado en una combinación de valores lean y ágiles, ScALed está basado en profesionales y se puede completar a través de varios marcos y prácticas ágiles.
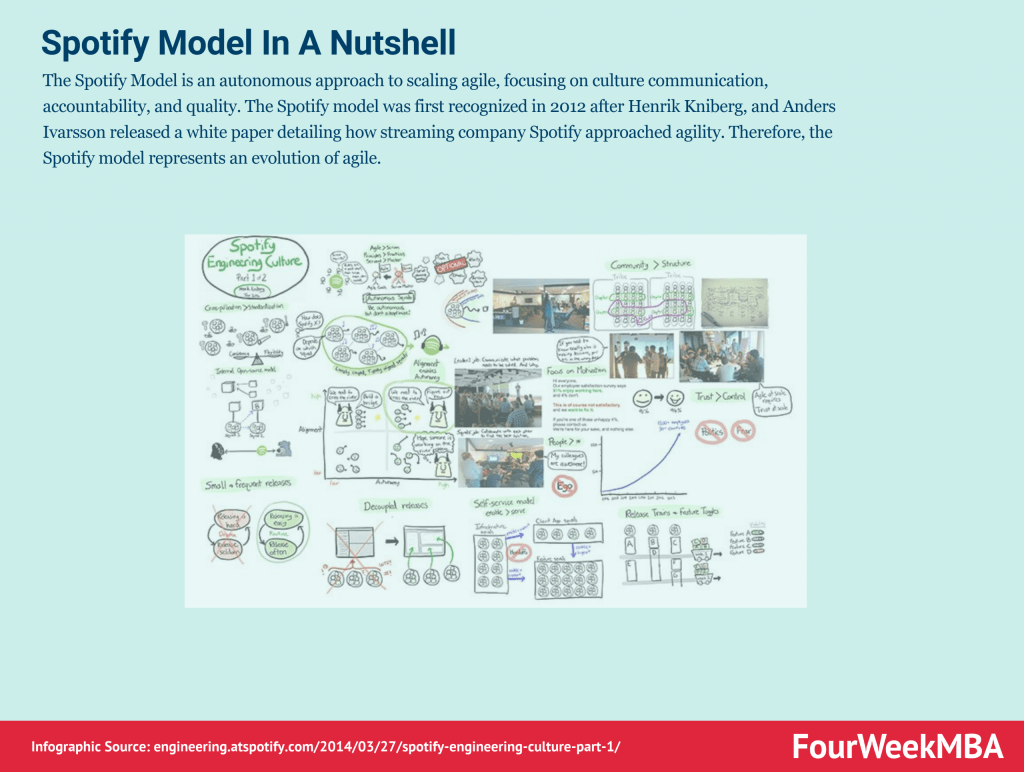
El modelo de Spotify es un enfoque autónomo para escalar ágilmente, centrándose en la comunicación cultural, la responsabilidad y la calidad. El modelo de Spotify fue reconocido por primera vez en 2012 después de Henrik Kniberg, y Anders Ivarsson publicó un informe técnico que detalla cómo la empresa de transmisión Spotify se acercó a la agilidad. Por lo tanto, el modelo de Spotify representa una evolución de ágil.
Como sugiere el nombre, TDD es una técnica basada en pruebas para entregar software de alta calidad de manera rápida y sostenible. Es un enfoque iterativo basado en la idea de que una prueba fallida debe escribirse antes de escribir cualquier código para una característica o función. Test-Driven Development (TDD) es un enfoque para el desarrollo de software que se basa en ciclos de desarrollo muy cortos.
Timeboxing es una técnica de gestión del tiempo simple pero poderosa para mejorar la productividad. Timeboxing describe el proceso de programar proactivamente un bloque de tiempo para dedicarlo a una tarea en el futuro. Fue descrito por primera vez por el autor James Martin en un libro sobre desarrollo de software ágil.
Scrum es una metodología co-creada por Ken Schwaber y Jeff Sutherland para la colaboración efectiva en equipo en productos complejos. Scrum se pensó principalmente para proyectos de desarrollo de software para ofrecer nuevas capacidades de software cada 2 a 4 semanas. Es un subgrupo de ágil que también se utiliza en la gestión de proyectos para mejorar la productividad de las nuevas empresas.
Scrumban es un marco de gestión de proyectos que es un híbrido de dos metodologías ágiles populares: Scrum y Kanban. Scrumban es un enfoque popular para ayudar a las empresas a concentrarse en las tareas estratégicas correctas y, al mismo tiempo, fortalecer sus procesos.
Los antipatrones de Scrum describen cualquier solución atractiva y fácil de implementar que, en última instancia, empeora un problema. Por lo tanto, estas son las prácticas que no se deben seguir para evitar que surjan problemas. Algunos ejemplos clásicos de antipatrones de scrum incluyen propietarios de productos ausentes, tickets preasignados (que hacen que las personas trabajen de forma aislada) y retrospectivas con descuento (donde las reuniones de revisión no son útiles para realizar mejoras).
Scrum at Scale (Scrum@Scale) es un marco que utilizan los equipos de Scrum para abordar problemas complejos y entregar productos de alto valor. Scrum at Scale se creó a través de una empresa conjunta entre Scrum Alliance y Scrum Inc. La empresa conjunta fue supervisada por Jeff Sutherland, co-creador de Scrum y uno de los principales autores del Manifiesto Ágil.
Los objetivos de extensión describen cualquier tarea que un equipo ágil planea completar sin comprometerse expresamente a hacerlo. Los equipos incorporan objetivos de extensión durante un Sprint o Incremento de programa (PI) como parte de Scaled Agile. Se utilizan cuando el equipo ágil no está seguro de su capacidad para alcanzar un objetivo. Por lo tanto, los objetivos de extensión son en cambio resultados que, si bien son extremadamente deseables, no son la diferencia entre el éxito o el fracaso de cada sprint.
El modelo de cascada fue descrito por primera vez por Herbert D. Benington en 1956 durante una presentación sobre el software utilizado en las imágenes de radar durante la Guerra Fría. Dado que no existían estrategias de desarrollo de software creativas basadas en el conocimiento en ese momento, el método de cascada se convirtió en una práctica estándar. El modelo de cascada es un marco de gestión de proyectos lineal y secuencial.
Gennaro es el creador de FourWeekMBA, que llegó a cerca de cuatro millones de empresarios, incluidos ejecutivos de nivel C, inversores, analistas, gerentes de productos y aspirantes a emprendedores digitales solo en 2022 | También es director de ventas de una ampliación de alta tecnología en la industria de la IA | En 2012, Gennaro obtuvo un MBA Internacional con énfasis en Finanzas Corporativas y Estrategia Comercial.
Descubre más de FourWeekMBA
Suscríbete ahora para seguir leyendo y obtener acceso al archivo completo.















































")




